Lyra是什么
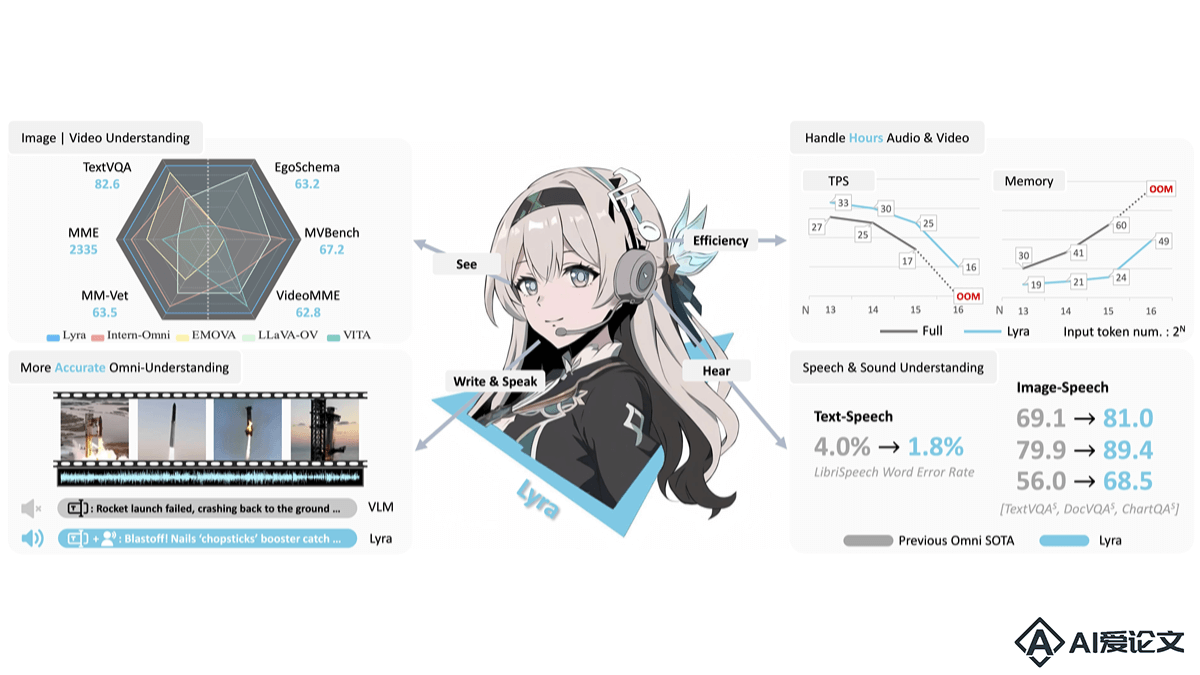
Lyra是香港中文大学、SmartMore和香港科技大学推出的高效多模态大型语言模型(MLLM),专注于提升语音、视觉和语言模态的交互能力。Lyra基于开源大型模型、多模态LoRA模块和潜在的多模态正则化器,减少训练成本和数据需求。Lyra构建大规模的多模态数据集,包括长语音样本,处理复杂的长语音输入,实现强大的全模态认知能力。在多种模态理解和推理任务中,Lyra达到最先进的性能,同时在计算资源和训练数据的使用上更为高效。
来源:爱论文 时间:2025-01-23 12:14:09
Lyra是香港中文大学、SmartMore和香港科技大学推出的高效多模态大型语言模型(MLLM),专注于提升语音、视觉和语言模态的交互能力。Lyra基于开源大型模型、多模态LoRA模块和潜在的多模态正则化器,减少训练成本和数据需求。Lyra构建大规模的多模态数据集,包括长语音样本,处理复杂的长语音输入,实现强大的全模态认知能力。在多种模态理解和推理任务中,Lyra达到最先进的性能,同时在计算资源和训练数据的使用上更为高效。
 相关资讯
更多+
相关资讯
更多+
Lyra是香港中文大学、SmartMore和香港科技大学推出的高效多模态大型语言模型(MLLM),专注于提升语音、视觉和语言模态的交互能力。Lyra基于开源大型模型、多模态LoRA模块和潜在的多模态正则化器,减少训练成本和数据需求。
AI教程资讯
 2023-04-14
2023-04-14
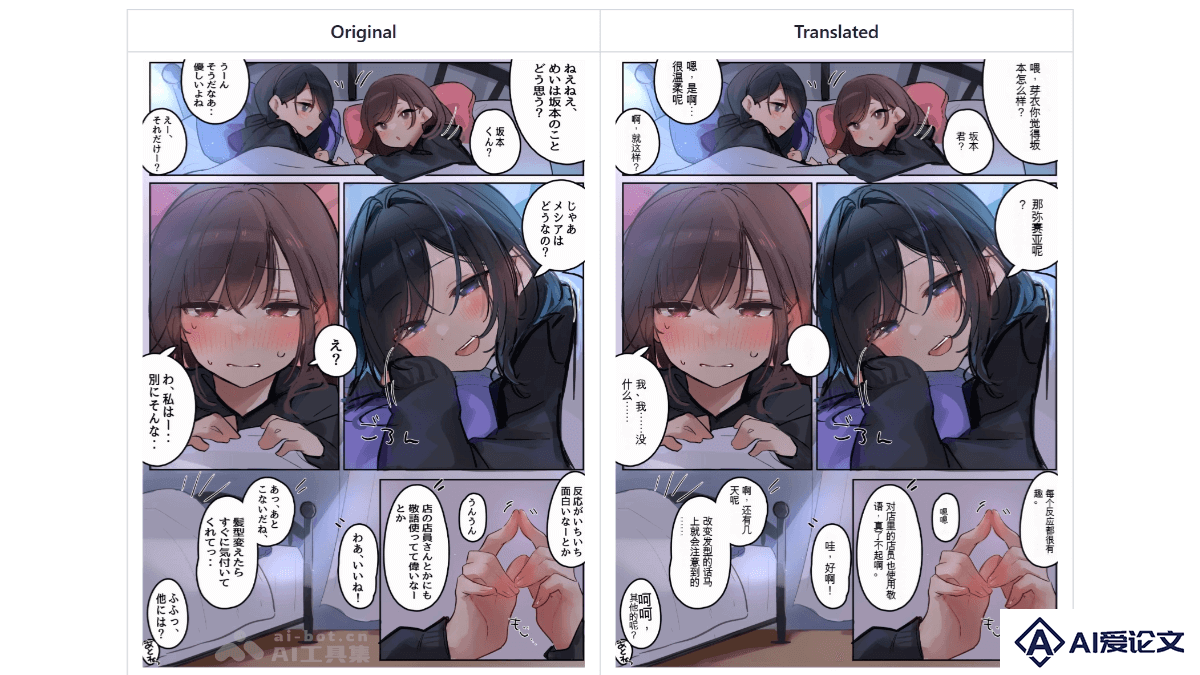
Manga Image Translator是开源的漫画图片文字翻译工具,能一键翻译漫画和图片中的文字。Manga Image Translator基于OCR技术识别文本,结合机器翻译将文字转换成目标语言。工具支持多种语言,能将翻译后的文本无缝嵌入原图,保持漫画风格。
AI教程资讯
2023-04-14

Ivy-VL是AI Safeguard联合卡内基梅隆大学和斯坦福大学推出的轻量级多模态AI模型,专为移动端和边缘设备设计。模型拥有3B参数量,相较于其他多模态大模型,显著降低计算资源需求,能在AI眼镜、智能手机等资源受限设备上高效运行。
AI教程资讯
2023-04-14

ColorFlow是清华大学和腾讯ARC实验室共同推出的图像序列着色模型,能精细化地保持图像序列中个体身份的同时进行着色。基于检索增强、上下文学习和超分辨率技术,ColorFlow确保黑白图像序列着色与参考图像颜色一致性,适用于漫画、动画制作等工业应用。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















