MV-Adapter是什么
MV-Adapter是多视图一致图像生成模型,是北京航空航天大学、VAST和上海交通大学的研究团队推出的。MV-Adapter能将预训练的文本到图像扩散模型转化为多视图图像生成器,无需改变原始网络结构或特征空间。MV-Adapter基于创新的注意力架构和统一条件编码器,高效地建模多视图一致性和参考图像的相关性,支持生成高分辨率的多视角图像,能适配多种定制模型和插件,实现广泛的应用场景。

来源:爱论文 时间:2025-01-22 17:42:57
MV-Adapter是多视图一致图像生成模型,是北京航空航天大学、VAST和上海交通大学的研究团队推出的。MV-Adapter能将预训练的文本到图像扩散模型转化为多视图图像生成器,无需改变原始网络结构或特征空间。MV-Adapter基于创新的注意力架构和统一条件编码器,高效地建模多视图一致性和参考图像的相关性,支持生成高分辨率的多视角图像,能适配多种定制模型和插件,实现广泛的应用场景。
 相关资讯
更多+
相关资讯
更多+
MV-Adapter是多视图一致图像生成模型,是北京航空航天大学、VAST和上海交通大学的研究团队推出的。MV-Adapter能将预训练的文本到图像扩散模型转化为多视图图像生成器,无需改变原始网络结构或特征空间。
AI教程资讯
 2023-04-14
2023-04-14

FACTS Grounding是谷歌DeepMind推出的评估大型语言模型(LLMs)能力的基准测试,衡量模型根据给定上下文生成事实准确且无捏造信息的文本的能力。FACTS Grounding测试集包含1719个跨多个领域的示例,要求模型响应必须基于长达32000个token的文档,涵盖摘要、问答和改写等任务。
AI教程资讯
2023-04-14

MarkItDown是微软开源的多功能文档处理工具,能将PDF、PPT、Word、Excel、图像、音频、HTML等多种格式的文件转换成Markdown格式。支持OCR文字识别、语音转文字和元数据提取,适用于内容索引、数据挖掘、文档处理等场景,极大地简化文件处理流程,提升工作效率。
AI教程资讯
2023-04-14
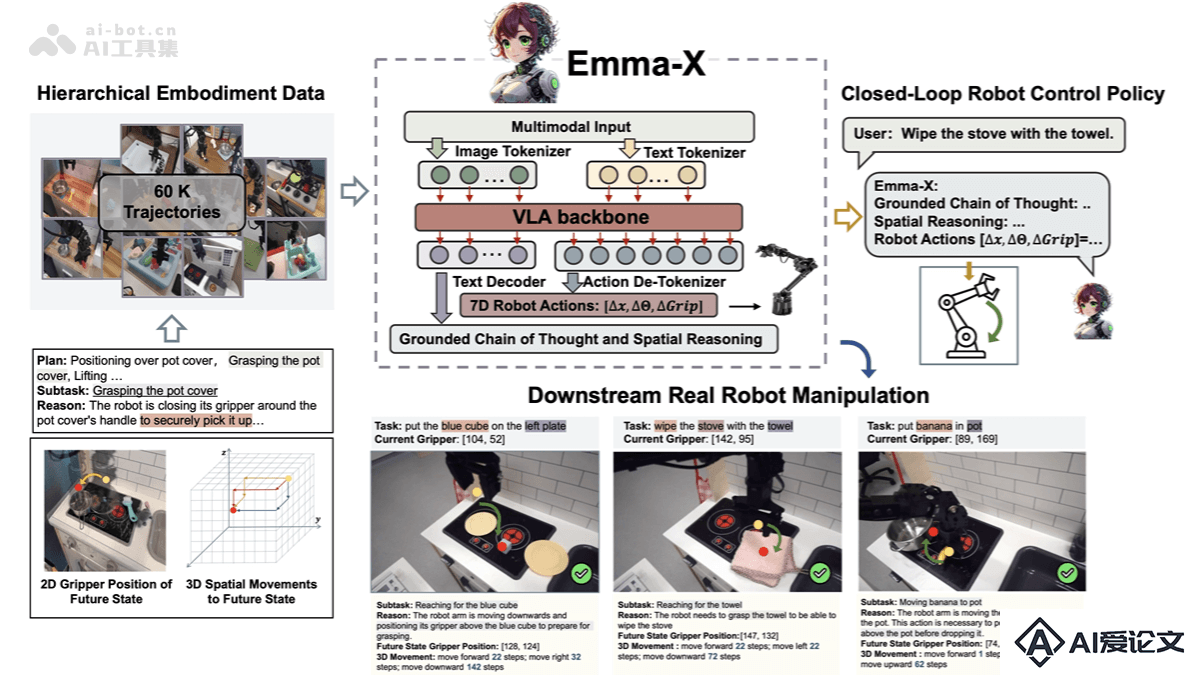
EMMA-X是新加坡科技设计大学推出的具有70亿参数的具身多模态动作模型,在有根据的链式思维(CoT)推理数据上微调OpenVLA创建。EMMA-X结合层次化的具身数据集,包含3D空间运动、2D夹爪位置和有根据的推理,及推出一种新颖的轨迹分割策略,用夹爪的开合状态和机器人手臂的运动轨迹,增强有根据的任务推理和前瞻性空间推理。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载













