EnerVerse是什么
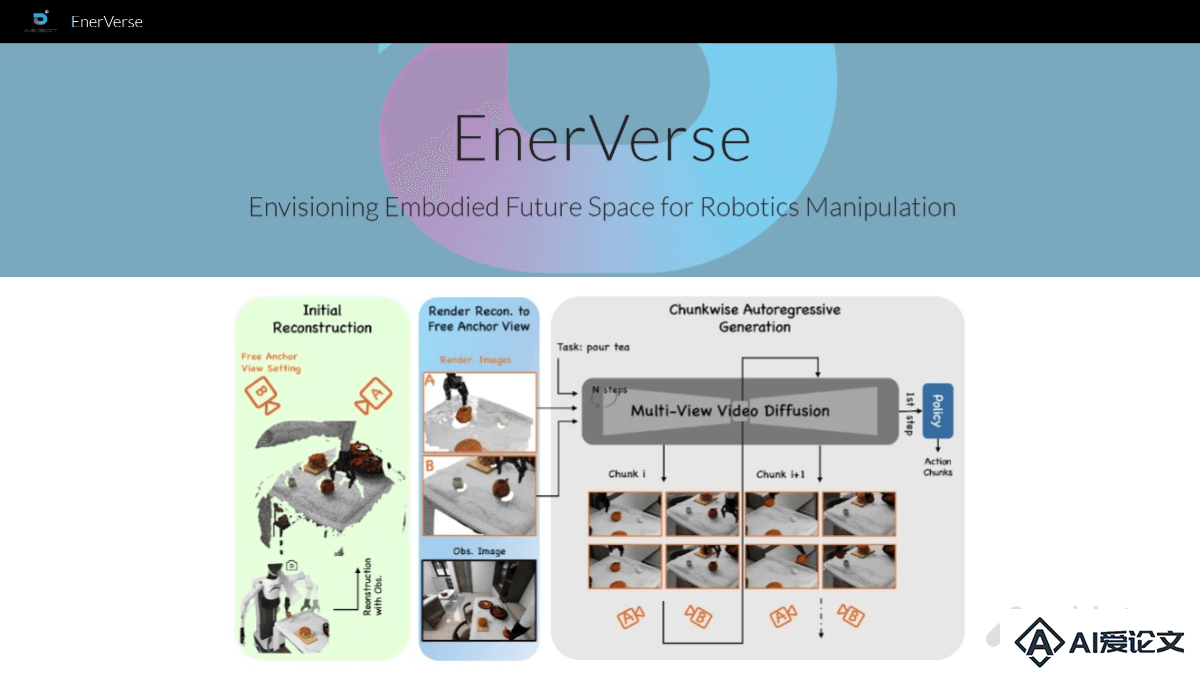
EnerVerse 是智元机器人团队开发的首个机器人4D世界模型,旨在通过生成未来具身空间来指导机器人完成复杂任务。模型采用自回归扩散模型,结合稀疏记忆机制(Sparse Memory)和自由锚定视角(Free Anchor View, FAV),显著提升4D生成能力和动作规划性能。实验结果表明,EnerVerse在机器人动作规划任务中达到了当前最优水平。目前,EnerVerse的项目主页和论文已经上线,模型与数据集即将开源。
来源:爱论文 时间:2025-01-13 17:57:44
EnerVerse 是智元机器人团队开发的首个机器人4D世界模型,旨在通过生成未来具身空间来指导机器人完成复杂任务。模型采用自回归扩散模型,结合稀疏记忆机制(Sparse Memory)和自由锚定视角(Free Anchor View, FAV),显著提升4D生成能力和动作规划性能。实验结果表明,EnerVerse在机器人动作规划任务中达到了当前最优水平。目前,EnerVerse的项目主页和论文已经上线,模型与数据集即将开源。
 相关资讯
更多+
相关资讯
更多+
EnerVerse 是智元机器人团队开发的首个机器人4D世界模型,旨在通过生成未来具身空间来指导机器人完成复杂任务。模型采用自回归扩散模型,结合稀疏记忆机制(Sparse Memory)和自由锚定视角(Free Anchor View, FAV),显著提升4D生成能力和动作规划性能。
AI教程资讯
 2023-04-14
2023-04-14

Seer是由上海AI实验室、北京大学计算机科学与技术学院、北京大学软件与微电子学院等机构联合推出的端到端操作模型,实现机器人视觉预测与动作执行的高度协同。模型结合历史信息和目标信号(如语言指令),预测未来时刻的状态,用逆动力学模型生成动作信号。Seer基于Transformer的结构,处理多模态输入数据,有效融合视觉、语言和机器人本体信号。
AI教程资讯
2023-04-14

ArtCrafter是清华大学、鹏城实验室和联想研究院共同推出的文本到图像风格迁移框架,基于扩散模型,解决传统方法在风格表达、内容一致性和输出多样性方面的局限。ArtCrafter基于嵌入重构架构实现,包含三个关键组件:基于注意力的风格提取模块,用多层架构和感知器注意力机制从参考图像中提取细腻的风格特征。
AI教程资讯
2023-04-14

Ingredients是强大的框架,基于将多个特定身份(ID)照片与视频扩散Transformer相结合,用在定制视频创作。Ingredients基于三个核心模块实现高度定制化的视频生成:面部提取器、多尺度投影器和ID路由器。面部提取器从全局和局部视角捕捉每个身份的面部特征;多尺度投影器将这些特征映射到视频扩散模型的上下文中;ID路由器则动态分配和组合多个身份特征到相应的时间空间区域。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载









