INFP是什么
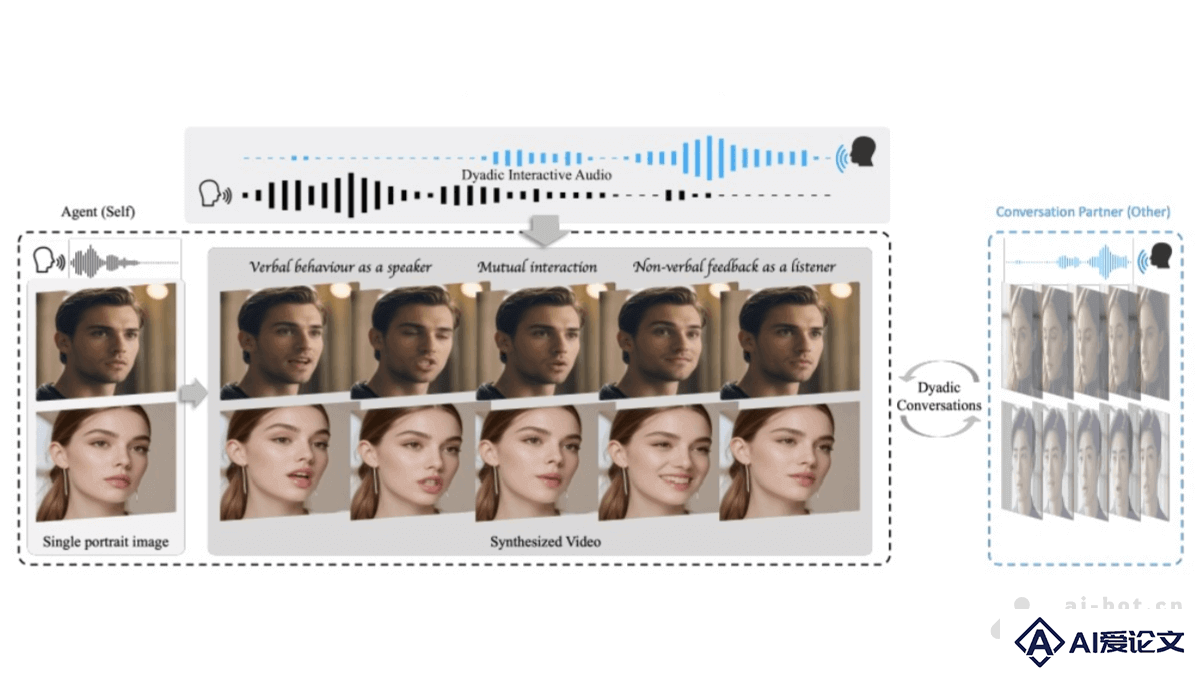
INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。INFP提出了大规模双人对话数据集DyConv,以支持该研究领域的进步。
来源:爱论文 时间:2025-01-22 10:55:44
INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。INFP提出了大规模双人对话数据集DyConv,以支持该研究领域的进步。
 相关资讯
更多+
相关资讯
更多+
INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。
AI教程资讯
 2023-04-14
2023-04-14

VisionFM(伏羲慧眼)是多模态多任务的视觉基础模型,专为通用眼科人工智能而设计。通过预训练3 4百万张来自560,457个个体的眼科图像,覆盖广泛的眼科疾病、成像模态、设备和人群统计数据。VisionFM能处理包括眼底摄影、光学相干断层扫描(OCT)、荧光素眼底血管造影(FFA)等在内的八种常见眼科成像模态,应用于眼科疾病识别、疾病进展预测、疾病表型细分以及全身生物标志物和疾病预测等多种眼科AI任务。
AI教程资讯
2023-04-14

MetaMorph是多模态大模型(MLLM),通过指令微调(Instruction Tuning)实现视觉理解和生成。它提出了一种名为Visual-Predictive Instruction Tuning(VPiT)的方法,使得预训练的大型语言模型(LLM)能够快速转变为一个统一的自回归模型,能生成文本和视觉token。
AI教程资讯
2023-04-14

AgentScope是阿里巴巴集团开源的多智能体开发平台,帮助开发者轻松构建和部署多智能体应用。AgentScope提供高易用性、高鲁棒性和分布式支持,内置多种模型API和本地模型部署选项,覆盖聊天、图像合成、文本嵌入等多种任务。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












