DisPose是什么
DisPose是北京大学、中国科学技术大学、清华大学和香港科技大学的研究团队共同推出的,提高人物图像动画质量的控制技术,基于从骨骼姿态和参考图像中提取有效的控制信号,无需额外的密集输入。DisPose将姿态控制分解为运动场引导和关键点对应,生成密集运动场以提供区域级引导,同时保持对不同体型的泛化能力。DisPose包括一个即插即用的混合ControlNet,能改善现有模型生成视频的质量和一致性。

来源:爱论文 时间:2025-01-21 14:07:54
DisPose是北京大学、中国科学技术大学、清华大学和香港科技大学的研究团队共同推出的,提高人物图像动画质量的控制技术,基于从骨骼姿态和参考图像中提取有效的控制信号,无需额外的密集输入。DisPose将姿态控制分解为运动场引导和关键点对应,生成密集运动场以提供区域级引导,同时保持对不同体型的泛化能力。DisPose包括一个即插即用的混合ControlNet,能改善现有模型生成视频的质量和一致性。
 相关资讯
更多+
相关资讯
更多+
DisPose是北京大学、中国科学技术大学、清华大学和香港科技大学的研究团队共同推出的,提高人物图像动画质量的控制技术,基于从骨骼姿态和参考图像中提取有效的控制信号,无需额外的密集输入。DisPose将姿态控制分解为运动场引导和关键点对应,生成密集运动场以提供区域级引导,同时保持对不同体型的泛化能力。
AI教程资讯
 2023-04-14
2023-04-14

OCTAVE(Omni-Capable Text and Voice Engine)是Hume AI推出的新一代语音语言模型,结合EVI 2模型和OpenAI、Elevenlab、Google Deepmind等系统的能力。OCTAVE能从简短提示或录音中生成个性化的声音和特质,包括语言、口音、情感等特征,支持实时互动和多角色对话。
AI教程资讯
2023-04-14

Granite 3 1是IBM推出的新一代语言模型,具有强大的性能和更长的上下文处理能力。Granite 3 1模型家族有 4 种不同的尺寸和 2 种架构:密集模型2B和8B参数模型,总共使用 12 万亿个token进行训练。专家混合MoE模型:稀疏1B和3B MoE 模型,分别具有 400M 和 800M 激活参数,总共使用 10 万亿个token进行训练。
AI教程资讯
2023-04-14
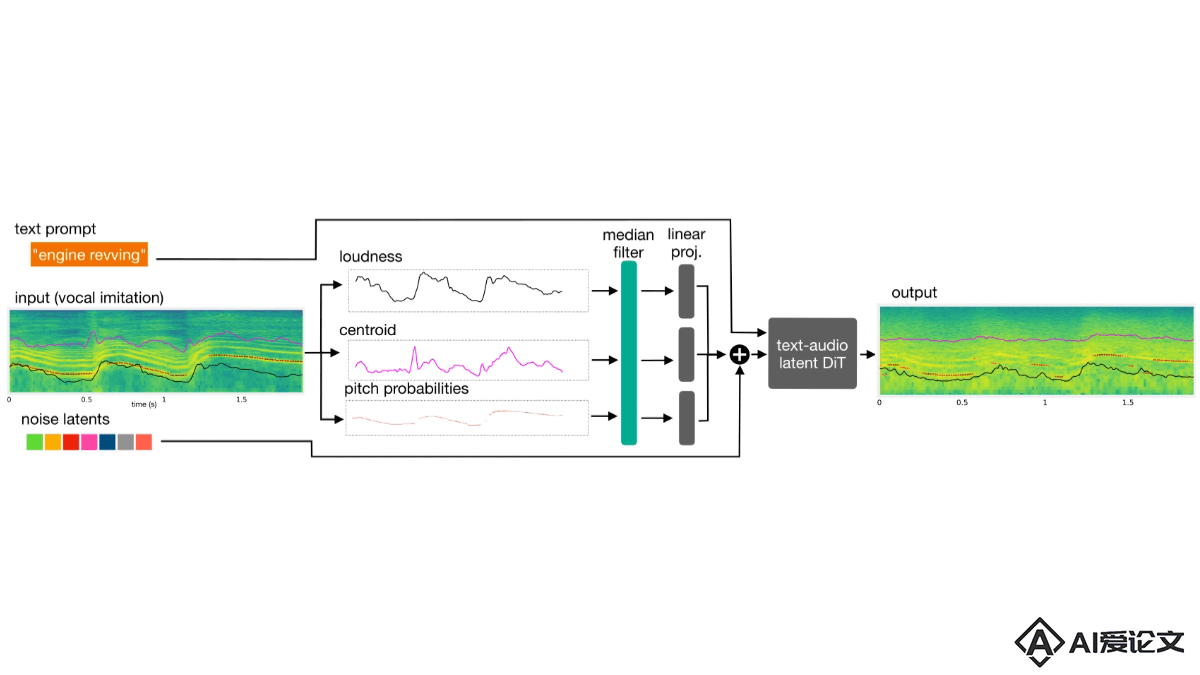
Sketch2Sound是Adobe 研究院和西北大学推出的AI音频生成技术,能基于声音模仿和文本提示生成高品质音效。Sketch2Sound从声音模仿中提取响度、亮度和音高三个控制信号,将控制信号编码后用于条件文本到声音的生成系统。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












