Sketch2Sound是什么
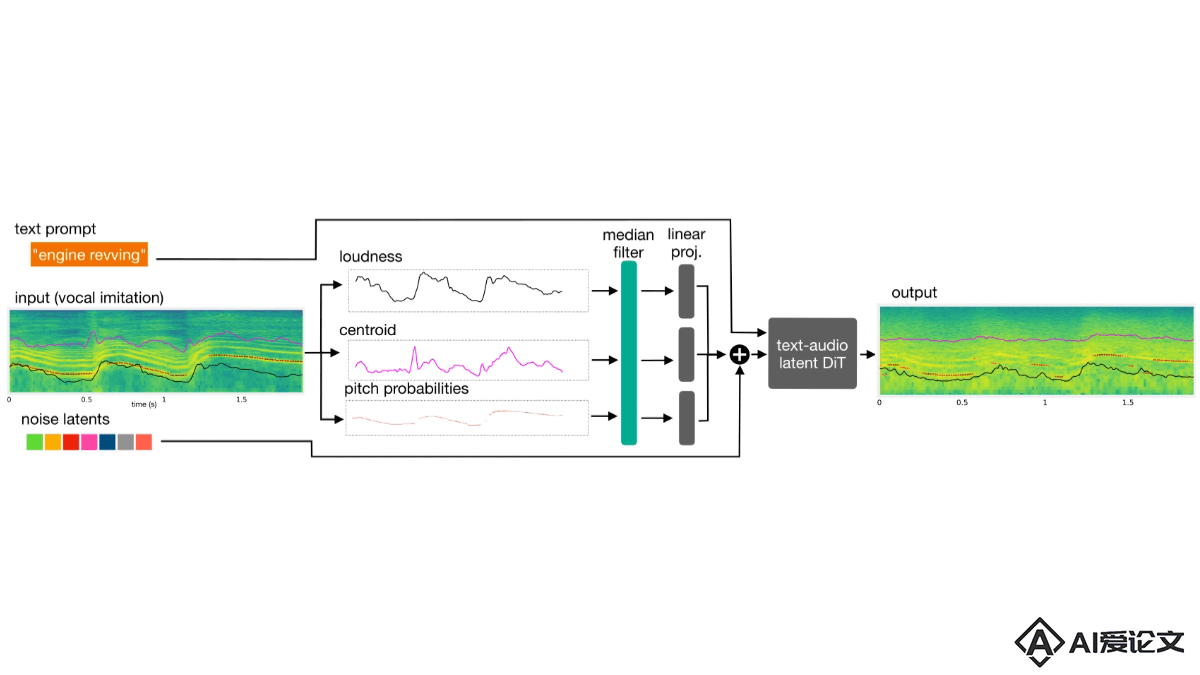
Sketch2Sound是Adobe 研究院和西北大学推出的AI音频生成技术,能基于声音模仿和文本提示生成高品质音效。Sketch2Sound从声音模仿中提取响度、亮度和音高三个控制信号,将控制信号编码后用于条件文本到声音的生成系统。Sketch2Sound轻量级,只需少量微调步骤和单层线性适配,即可在多种文本到音频模型上实现。Sketch2Sound为声音设计师提供结合文本提示的语义灵活性和声音模仿的精确性的工具,增强了声音创作的表达力和可控性。
来源:爱论文 时间:2025-01-21 12:52:27
Sketch2Sound是Adobe 研究院和西北大学推出的AI音频生成技术,能基于声音模仿和文本提示生成高品质音效。Sketch2Sound从声音模仿中提取响度、亮度和音高三个控制信号,将控制信号编码后用于条件文本到声音的生成系统。Sketch2Sound轻量级,只需少量微调步骤和单层线性适配,即可在多种文本到音频模型上实现。Sketch2Sound为声音设计师提供结合文本提示的语义灵活性和声音模仿的精确性的工具,增强了声音创作的表达力和可控性。
 相关资讯
更多+
相关资讯
更多+
Sketch2Sound是Adobe 研究院和西北大学推出的AI音频生成技术,能基于声音模仿和文本提示生成高品质音效。Sketch2Sound从声音模仿中提取响度、亮度和音高三个控制信号,将控制信号编码后用于条件文本到声音的生成系统。
AI教程资讯
 2023-04-14
2023-04-14

OmniAudio-2 6B是Nexa AI推出的音频语言模型,专为边缘部署设计,能实现快速且高效的音频文本处理。OmniAudio-2 6B是具有2 6亿参数的多模态模型融合Gemma-2-2b、Whisper Turbo和定制的投影模块,优化自动语音识别和语言模型的集成,减少延迟和资源消耗。
AI教程资讯
2023-04-14

DreamOmni 是香港中文大学、字节跳动和香港科技大学共同推出的统一图像生成和编辑模型。模型整合文本到图像(T2I)生成和多种编辑任务,包括指令式编辑、修复、拖拽编辑和参考图像生成。DreamOmni 基于一个高效的合成数据管道解决高质量编辑数据的创建难题,支持模型训练和扩展。
AI教程资讯
2023-04-14

QVQ是阿里基于Qwen2-VL-72B构建的开源多模态推理模型,结合视觉理解和复杂问题解决能力,提升人工智能的认知能力。QVQ在视觉推理任务中展现出增强的能力,尤其在需要复杂分析思维的领域表现出色。QVQ在MMMU评测中取得了70 3的高分,在各项数学相关基准测试中相比Qwen2-VL-72B-Instruct 有显著提升。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












