GR00T N1 – 英伟达开源的人形机器人基础模型
来源:爱论文
时间:2025-04-21 11:07:07
GR00T N1是什么
GR00T N1 是英伟达推出的全球首个开源基础模型,专为通用人形机器人设计。基于多模态输入(如语言和图像)实现多样化环境中的操作任务。GR00T N1 基于大规模人形机器人数据集训练,结合真实数据、合成数据和互联网视频数据,用后训练适应特定机器人形态、任务和环境。GR00T N1 基于双系统架构,视觉-语言模型负责推理和规划,扩散变换器则生成精确动作。GR00T N1 在模拟和真实世界测试中表现出色,在复杂多步任务和精准操作中优势明显,为材料处理、包装和检查等应用提供高效解决方案。

GR00T N1的主要功能
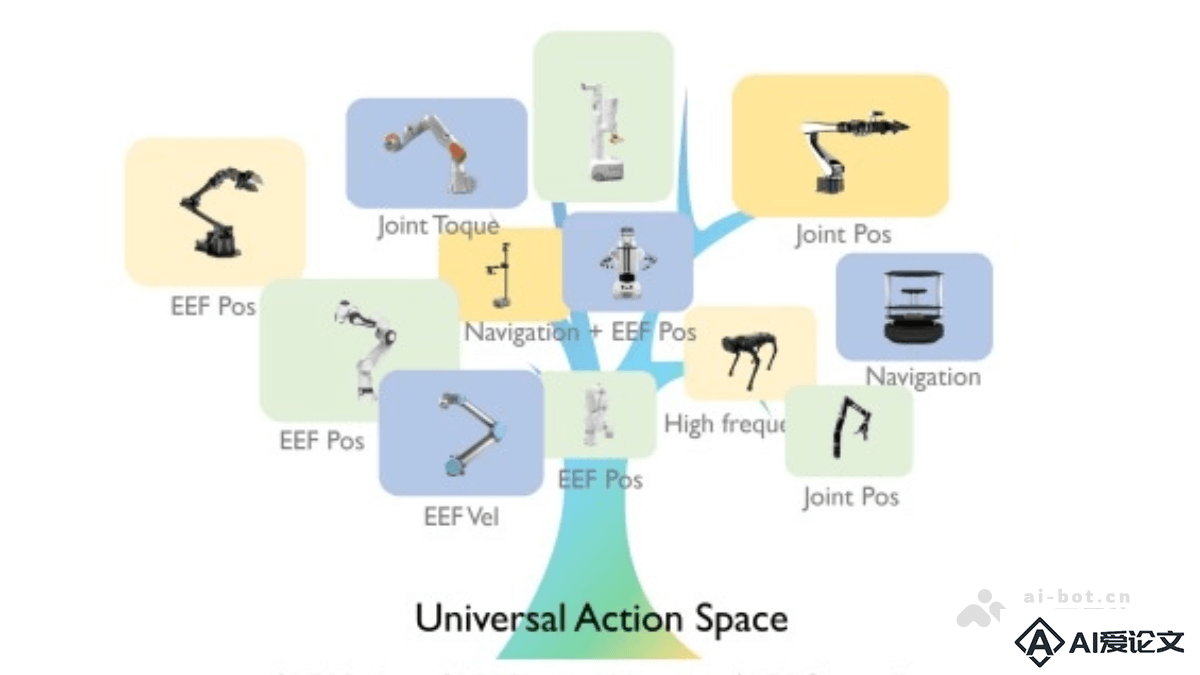
通用操作任务执行:在多样化环境中执行各种操作任务,例如抓取、搬运、双臂协调操作等。多模态输入处理:同时处理语言指令和视觉图像,机器人根据自然语言指令执行复杂的操作任务。跨机器人形态适应性:适应不同类型的机器人平台(如 Fourier GR-1 和 1X Neo),实现通用性。复杂任务推理与规划:执行需要持续上下文理解和多种技能整合的复杂多步任务。高效数据利用与训练:结合互联网规模数据、合成数据和真实机器人数据进行预训练,显著提升性能和泛化能力,减少对大规模标注数据的依赖。
GR00T N1的技术原理
双系统架构:视觉-语言模型(System 2):基于 NVIDIA-Eagle 和 SmolLM-1.7B 构建,负责用视觉和语言指令理解环境,进行推理和规划,输出动作计划。扩散变换器(System 1):作为动作模型,将视觉-语言模型的计划转化为精确的连续动作,控制机器人运动。数据策略:预训练数据包括互联网视频数据(提供人类动作模式和任务语义)、合成数据(基于 NVIDIA Omniverse 平台生成,补充运动控制信号)和真实机器人数据(遥操作收集,确保模型适应真实环境)。无监督学习从大规模未标注的人类视频数据中提取运动模式,提升机器人学习效率。模型训练与优化:在大规模数据上进行预训练,学习通用的运动和操作模式。针对特定机器人平台、任务和环境进行微调,进一步提升模型的适应性和性能。在推理阶段,减少扩散步骤等方式优化计算效率,确保实时性。
GR00T N1的项目地址
项目官网:https://developer.nvidia.com/isaac/gr00tGitHub仓库:https://github.com/NVIDIA/Isaac-GR00T/HuggingFace模型库:https://huggingface.co/nvidia/GR00T-N1技术论文:https://research.nvidia.com/publication/2025-03_nvidia-isaac-gr00t-n1
GR00T N1的应用场景
物流与仓储:用于抓取、搬运和分拣货物,自动盘点库存,优化货物存储和管理。制造业:执行零部件的精准装配,进行产品质量检测,提升生产效率和质量控制。零售行业:自动整理货架、补货,为顾客提供信息查询和商品推荐服务,提升购物体验。医疗保健:辅助患者进行康复训练,搬运和管理医疗物资,减轻医护人员负担。工业检查与维护:对设备进行巡检,发现异常并报告;执行简单的维护操作,降低人工成本。

 相关资讯
相关资讯 2023-04-14
2023-04-14


 下载
下载