Step-Video-TI2V是什么
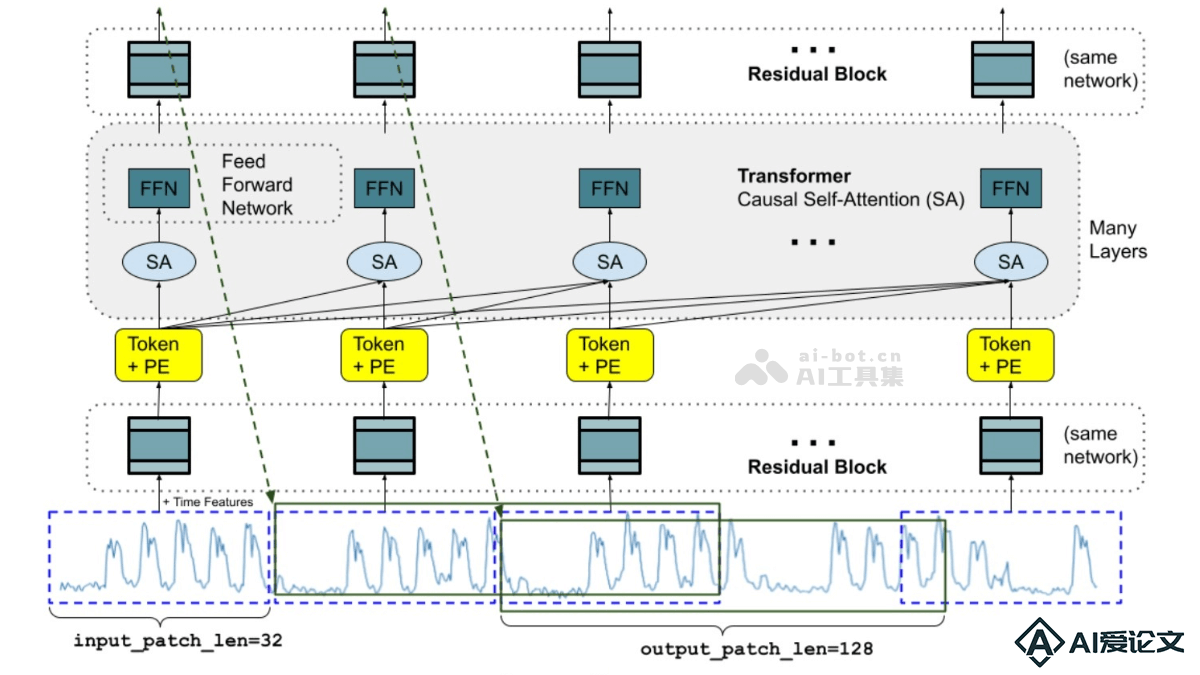
Step-Video-TI2V 是阶跃星辰(StepFun)推出的开源图生视频(Image-to-Video)生成模型,拥有 300 亿参数,能根据文本描述和图像输入生成最长 102 帧的视频。模型基于深度压缩的变分自编码器(Video-VAE),实现了 16×16 的空间压缩和 8× 的时间压缩,显著提高了训练和推理效率。用户可以通过设置运动分数(motion score)来平衡视频的动态性和稳定性。支持推、拉、摇、移、旋转、跟随等多种镜头运动方式。

来源:爱论文 时间:2025-04-20 12:11:02
Step-Video-TI2V 是阶跃星辰(StepFun)推出的开源图生视频(Image-to-Video)生成模型,拥有 300 亿参数,能根据文本描述和图像输入生成最长 102 帧的视频。模型基于深度压缩的变分自编码器(Video-VAE),实现了 16×16 的空间压缩和 8× 的时间压缩,显著提高了训练和推理效率。用户可以通过设置运动分数(motion score)来平衡视频的动态性和稳定性。支持推、拉、摇、移、旋转、跟随等多种镜头运动方式。
 相关资讯
更多+
相关资讯
更多+
Step-Video-TI2V 是阶跃星辰(StepFun)推出的开源图生视频(Image-to-Video)生成模型,拥有 300 亿参数,能根据文本描述和图像输入生成最长 102 帧的视频。模型基于深度压缩的变分自编码器(Video-VAE),实现了 16×16 的空间压缩和 8× 的时间压缩,显著提高了训练和推理效率。
AI教程资讯
 2023-04-14
2023-04-14

Dify-Plus 是基于 Dify 二次开发的企业级增强版项目,集成基于 gin-vue-admin 的管理中心。Dify-Plus在 Dify 基础上新增用户额度、密钥额度、Web 公开页登录鉴权、应用中心等功能,优化了权限管理,适合企业场景使用。
AI教程资讯
2023-04-14

gpt-4o-transcribe是 OpenAI 推出的高性能语音转文本模型。基于最新的语音模型架构,用海量多样化音频数据训练,精准捕捉语音细微差别,显著降低单词错误率(WER),优于前代 Whisper 模型。模型支持多种语言和方言,适合处理口音多样、环境嘈杂、语速变化等复杂场景,如呼叫中心、会议记录等。
AI教程资讯
2023-04-14

GPT-4o mini TTS 是 OpenAI 推出的轻量级文本转语音模型,支持将文本内容转换为自然流畅语音的同时,开发者能用指令控制语音的语调、情感和风格,例如“平静”“鼓励”“严肃”等,适应不同场景需求。模型基于先进语音合成技术,生成高质量语音输出,支持多种语言及不同性别、年龄和口音的语音,满足多样化用户需求。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载