Motia是什么
Motia 是专为软件工程师设计的 AI Agent 框架,简化 AI 智能体的开发、测试和部署过程。支持多种编程语言,如 Python、TypeScript 和 Ruby,开发者可以使用熟悉的语言编写智能体逻辑,无需学习专有领域特定语言。Motia 提供零基础设施部署,无需复杂配置可一键部署智能体。
来源:爱论文 时间:2025-04-19 13:26:45
Motia 是专为软件工程师设计的 AI Agent 框架,简化 AI 智能体的开发、测试和部署过程。支持多种编程语言,如 Python、TypeScript 和 Ruby,开发者可以使用熟悉的语言编写智能体逻辑,无需学习专有领域特定语言。Motia 提供零基础设施部署,无需复杂配置可一键部署智能体。
 相关资讯
更多+
相关资讯
更多+
Motia 是专为软件工程师设计的 AI Agent 框架,简化 AI 智能体的开发、测试和部署过程。支持多种编程语言,如 Python、TypeScript 和 Ruby,开发者可以使用熟悉的语言编写智能体逻辑,无需学习专有领域特定语言。
AI教程资讯
 2023-04-14
2023-04-14

InfiniteYou(InfU)是字节跳动智能创作团队推出的基于扩散变换器(Diffusion Transformers,如 FLUX)的身份保持图像生成框架。基于 InfuseNet 将身份特征注入扩散模型,增强身份相似度,保持图像生成能力。
AI教程资讯
2023-04-14

RuoYi AI 是全栈式 AI 开发平台,提供完整的前端、后台管理及小程序应用,支持灵活修改和分发代码。RuoYi AI 支持本地 RAG 方案,集成 Milvus Weaviate 等向量库,保障数据隐私与性能。平台内置 SSE、websocket 等网络协议,能对接 OpenAI、ChatGLM 等数十种大语言模型。
AI教程资讯
2023-04-14
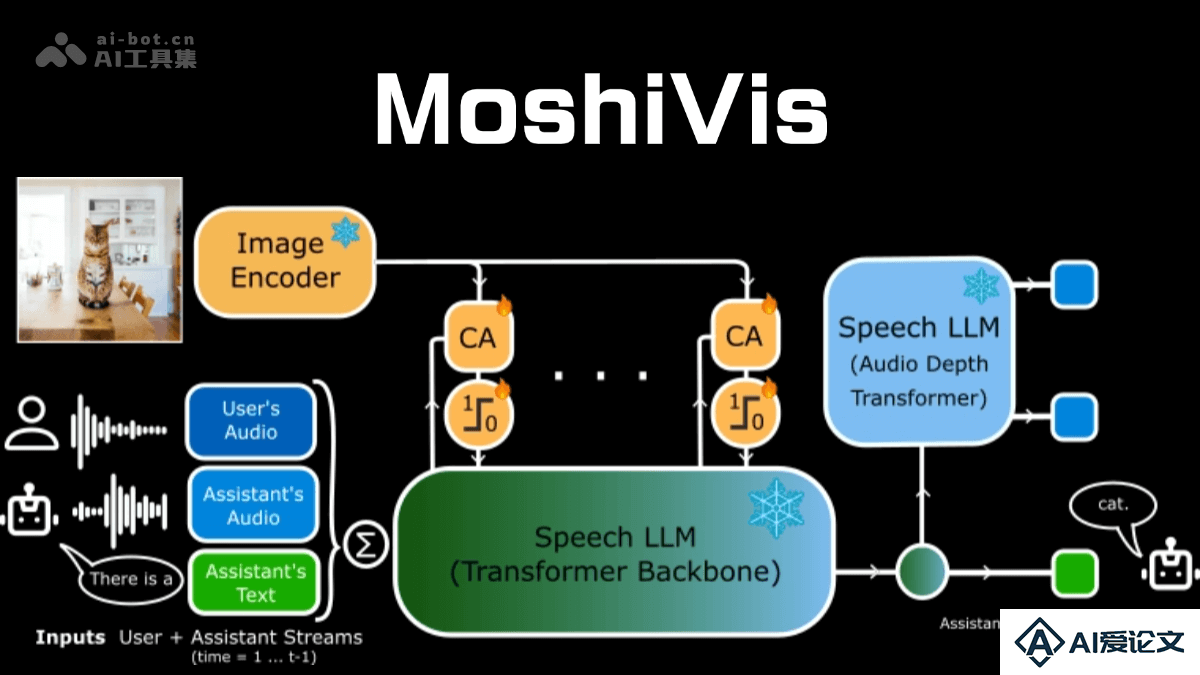
MoshiVis 是 Kyutai 推出的开源多模态语音模型,基于 Moshi 实时对话语音模型开发,增加了视觉输入功能。能实现图像的自然、实时语音交互,将语音和视觉信息相结合,让用户可以通过语音与模型交流图像内容。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载