DreamActor-M1是什么
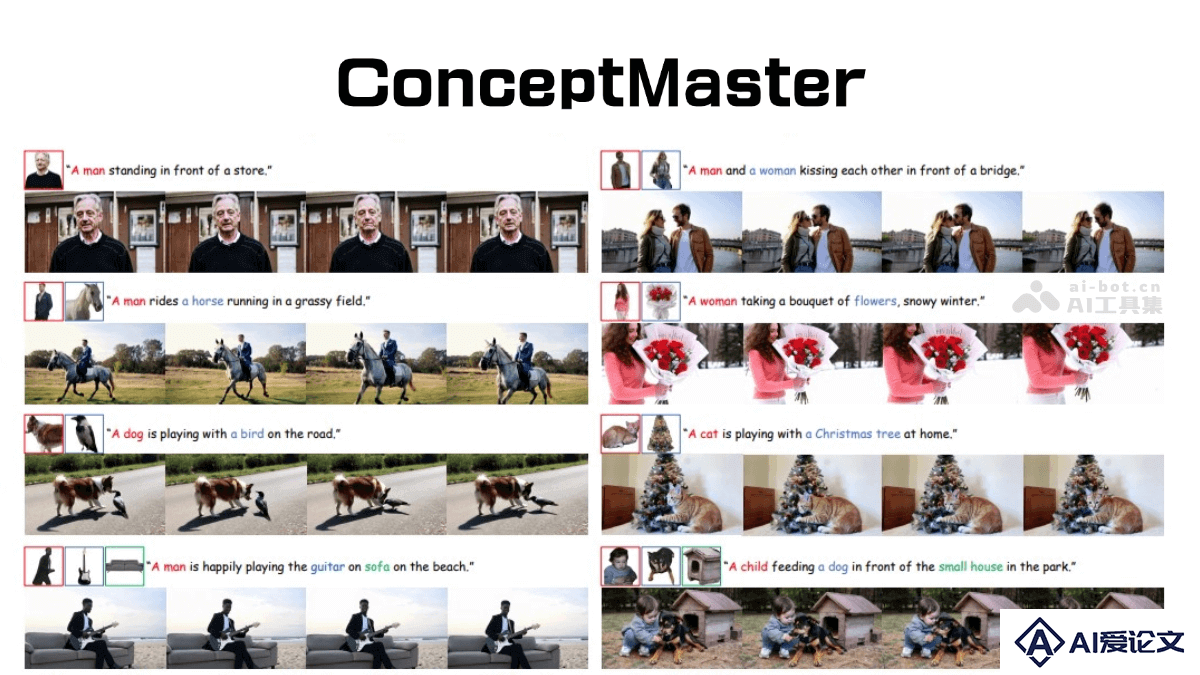
DreamActor-M1是字节跳动推出的先进AI图像动画框架,能将静态人物照片转化为生动的动画视频。采用混合引导机制,结合隐式面部表示、3D头部球体和3D身体骨架等控制信号,实现对人物面部表情和身体动作的精准控制。支持多语言语音驱动面部动画,可生成口型同步结果。 DreamActor-M1具有高保真度和身份保持能力,生成的视频在时间上连贯性强。

来源:爱论文 时间:2025-04-15 16:45:44
DreamActor-M1是字节跳动推出的先进AI图像动画框架,能将静态人物照片转化为生动的动画视频。采用混合引导机制,结合隐式面部表示、3D头部球体和3D身体骨架等控制信号,实现对人物面部表情和身体动作的精准控制。支持多语言语音驱动面部动画,可生成口型同步结果。 DreamActor-M1具有高保真度和身份保持能力,生成的视频在时间上连贯性强。
 相关资讯
更多+
相关资讯
更多+
DreamActor-M1是字节跳动推出的先进AI图像动画框架,能将静态人物照片转化为生动的动画视频。采用混合引导机制,结合隐式面部表示、3D头部球体和3D身体骨架等控制信号,实现对人物面部表情和身体动作的精准控制。
AI教程资讯
 2023-04-14
2023-04-14
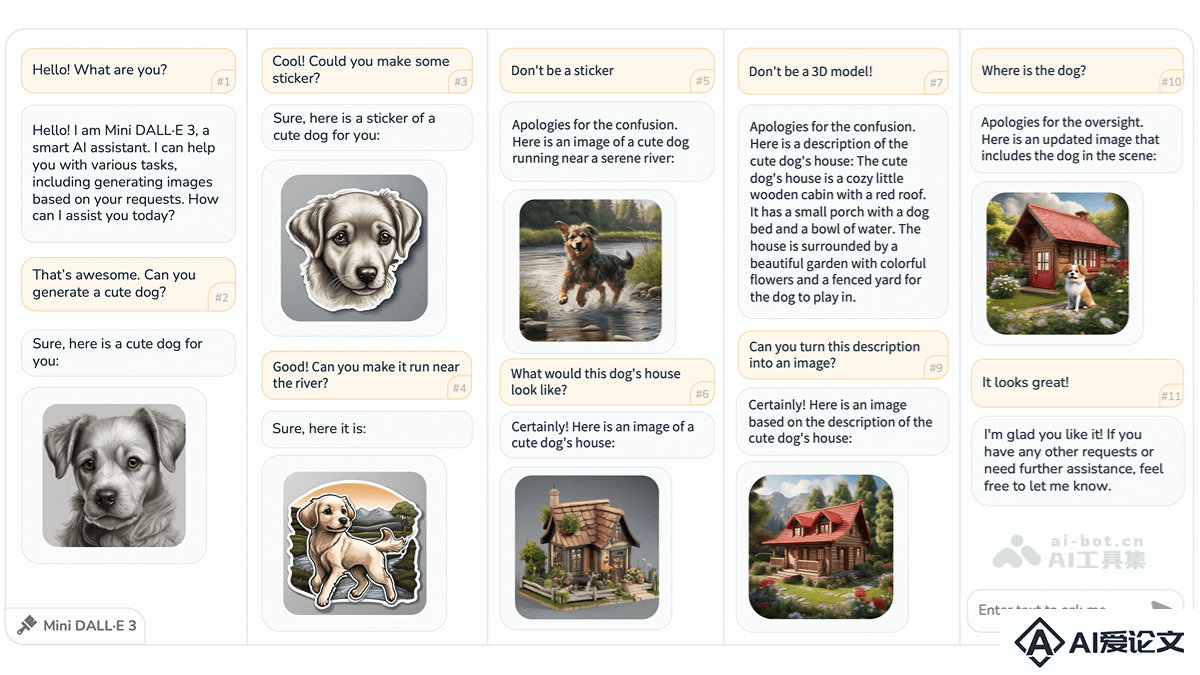
Mini DALL·E 3 是北京理工大学、上海AI Lab、清华大学和香港中文大学联合推出的交互式文本到图像(iT2I)框架。基于自然语言与用户进行多轮对话,实现高质量图像的生成、编辑和优化。
AI教程资讯
2023-04-14

MoCha AI 是 Meta 和滑铁卢大学联合开发的端到端对话角色视频生成模型。能根据文本或语音输入生成带有同步语音和自然动作的完整角色动画。MoCha 采用语音-视频窗口注意力机制,解决了视频压缩时音频分辨率不匹配以及唇部动作错位的问题。
AI教程资讯
2023-04-14

DeepSeek-GRM是DeepSeek和清华大学研究者共同提出的通用奖励模型(Generalist Reward Modeling)。通过点式生成式奖励建模(Pointwise Generative Reward Modeling, GRM)和自我原则点评调优(Self-Principled Critique Tuning, SPCT)等技术,显著提升了奖励模型的质量和推理时的可扩展性。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载