OmniTalker是什么
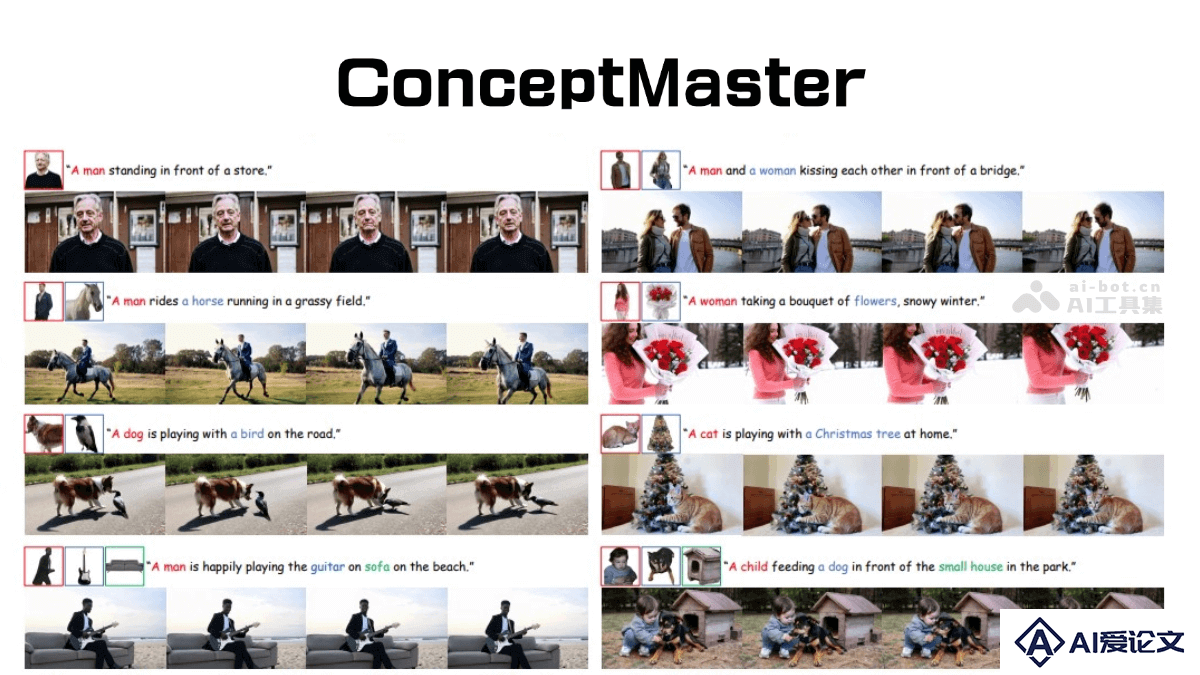
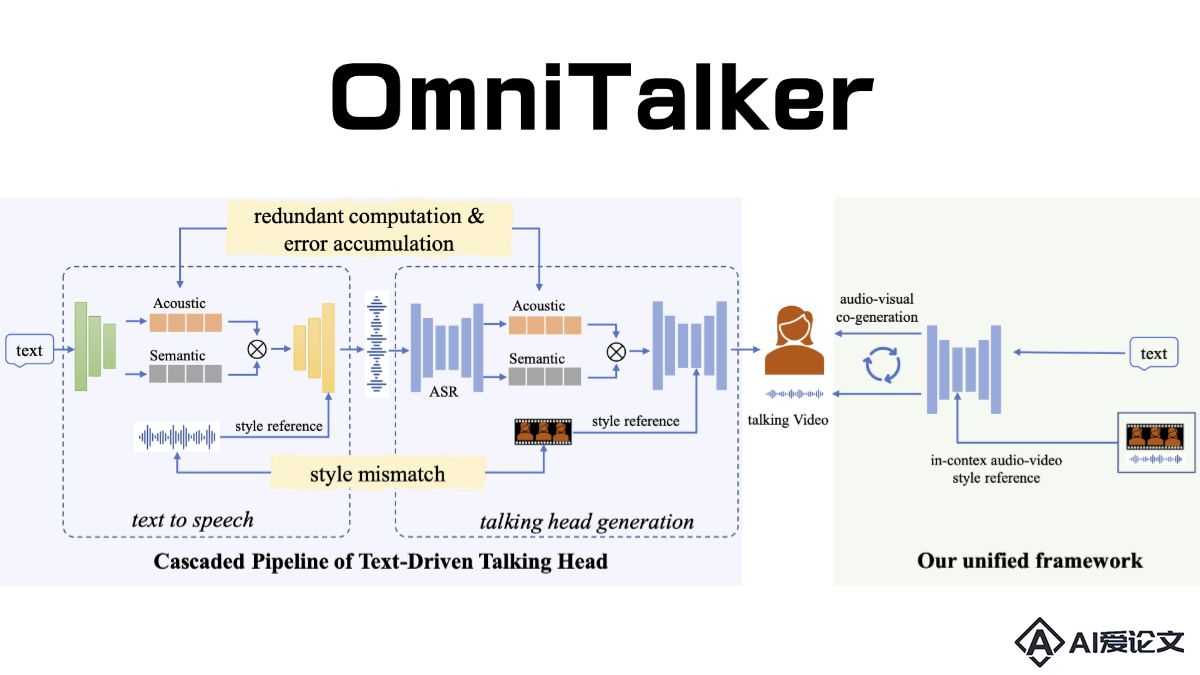
OmniTalker 是阿里巴巴发布的实时文本驱动的说话头像生成技术,能同时处理文本、图像、音频和视频等多种模态输入,以流式方式生成自然语音响应。核心架构为 Thinker-Talker 架构,Thinker 负责处理多模态输入并生成语义表征和文本内容,Talker 将这些信息转化为流畅的语音输出。OmniTalker 采用了 TMRoPE(时间对齐多模态旋转位置嵌入)技术,确保视频与音频输入的精准同步。
来源:爱论文 时间:2025-04-15 13:10:49
OmniTalker 是阿里巴巴发布的实时文本驱动的说话头像生成技术,能同时处理文本、图像、音频和视频等多种模态输入,以流式方式生成自然语音响应。核心架构为 Thinker-Talker 架构,Thinker 负责处理多模态输入并生成语义表征和文本内容,Talker 将这些信息转化为流畅的语音输出。OmniTalker 采用了 TMRoPE(时间对齐多模态旋转位置嵌入)技术,确保视频与音频输入的精准同步。
 相关资讯
更多+
相关资讯
更多+
OmniTalker 是阿里巴巴发布的实时文本驱动的说话头像生成技术,能同时处理文本、图像、音频和视频等多种模态输入,以流式方式生成自然语音响应。核心架构为 Thinker-Talker 架构,Thinker 负责处理多模态输入并生成语义表征和文本内容,Talker 将这些信息转化为流畅的语音输出。
AI教程资讯
 2023-04-14
2023-04-14
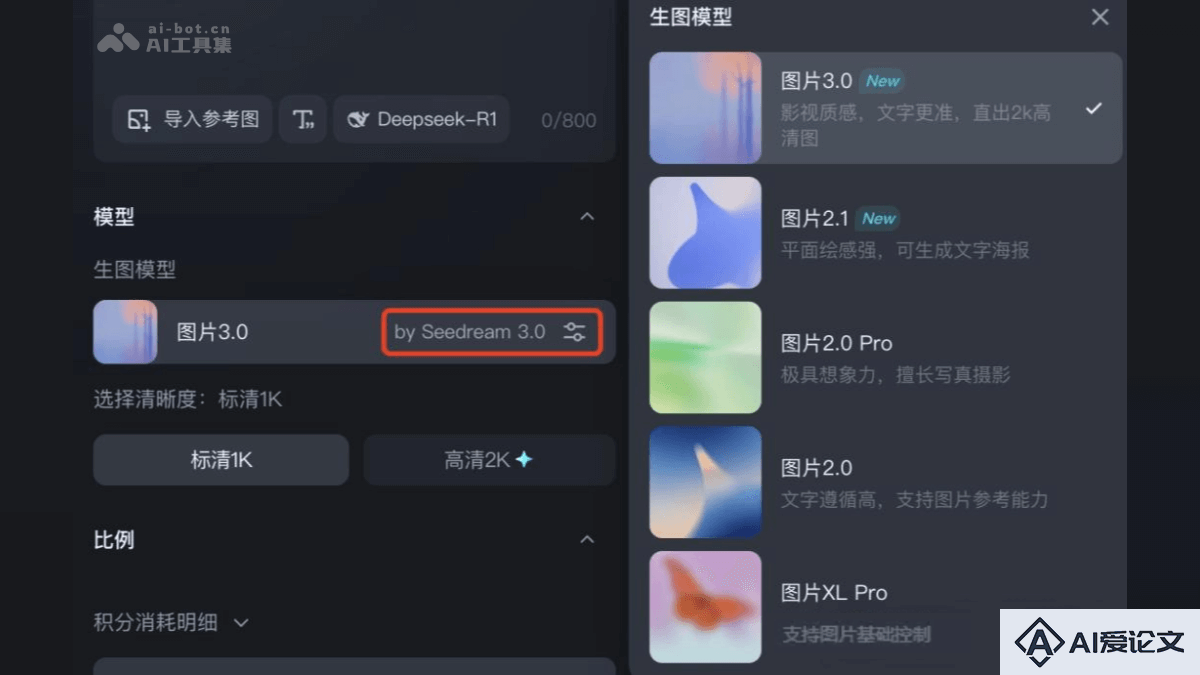
Seedream 3 0(即梦3 0)是字节跳动推出的AI图片生成模型,在中文文字生成和设计感方面表现出色,解决小字生成的稳定性问题,能精准生成复杂的中文内容,提供丰富的字体设计效果。Seedream 3 0图像质量最高可达2K分辨率,生成速度快且稳定。
AI教程资讯
2023-04-14

Quasar Alpha 是支持 100 万 token 的超大上下文窗口的预发布版 AI 模型,可处理超长文本和复杂文档。代码生成能力出色,生成速度快,延迟低,指令遵循能力强,支持联网功能和多模态功能,安全性也有所增强。
AI教程资讯
2023-04-14
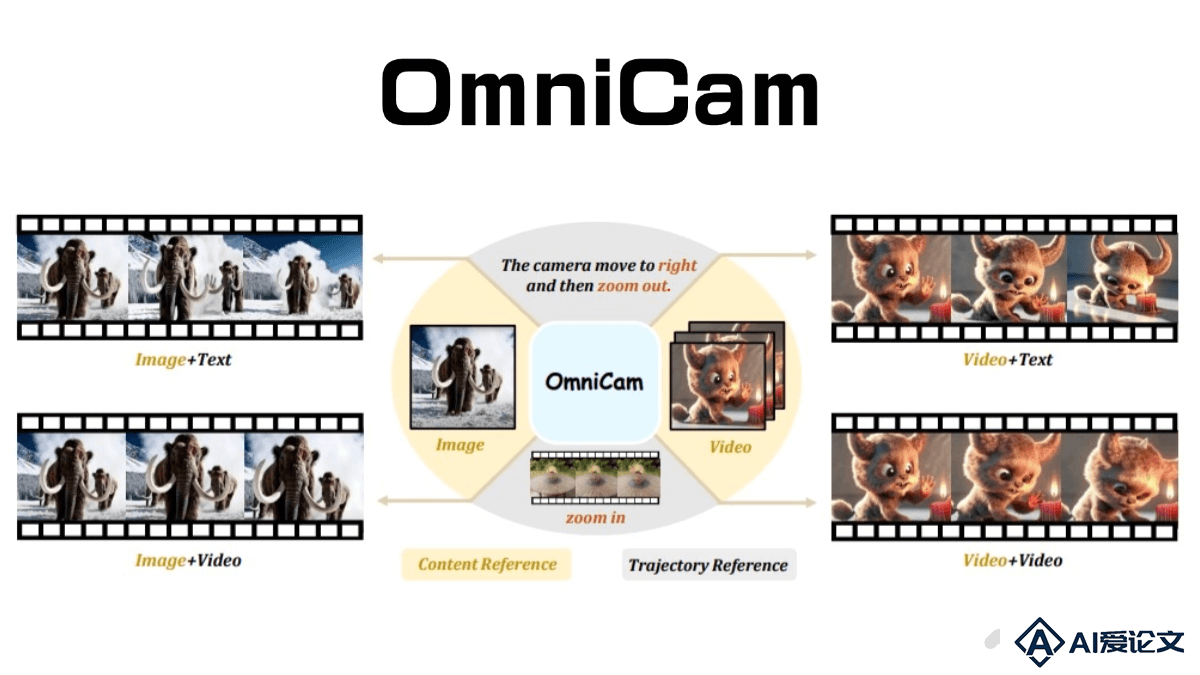
OmniCam 是先进的多模态视频生成框架,通过摄像机控制实现高质量的视频生成。支持多种输入模态组合,用户可以提供文本描述、视频中的轨迹或图像作为参考,精确控制摄像机的运动轨迹。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载