MT-MegatronLM是什么
MT-MegatronLM 是摩尔线程推出的面向全功能 GPU 的开源混合并行训练框架,主要用于高效训练大规模语言模型。支持 dense 模型、多模态模型及 MoE(混合专家)模型的训练。框架基于全功能 GPU 支持 FP8 混合精度策略、高性能算子库和集合通信库,显著提升了 GPU 集群的算力利用率。通过模型并行、数据并行和流水线并行等技术,实现了高效的分布式训练,支持混合精度训练以减少内存占用和加速计算。

来源:爱论文 时间:2025-04-12 11:20:08
MT-MegatronLM 是摩尔线程推出的面向全功能 GPU 的开源混合并行训练框架,主要用于高效训练大规模语言模型。支持 dense 模型、多模态模型及 MoE(混合专家)模型的训练。框架基于全功能 GPU 支持 FP8 混合精度策略、高性能算子库和集合通信库,显著提升了 GPU 集群的算力利用率。通过模型并行、数据并行和流水线并行等技术,实现了高效的分布式训练,支持混合精度训练以减少内存占用和加速计算。
 相关资讯
更多+
相关资讯
更多+
MT-MegatronLM 是摩尔线程推出的面向全功能 GPU 的开源混合并行训练框架,主要用于高效训练大规模语言模型。支持 dense 模型、多模态模型及 MoE(混合专家)模型的训练。框架基于全功能 GPU 支持 FP8 混合精度策略、高性能算子库和集合通信库,显著提升了 GPU 集群的算力利用率。
AI教程资讯
 2023-04-14
2023-04-14
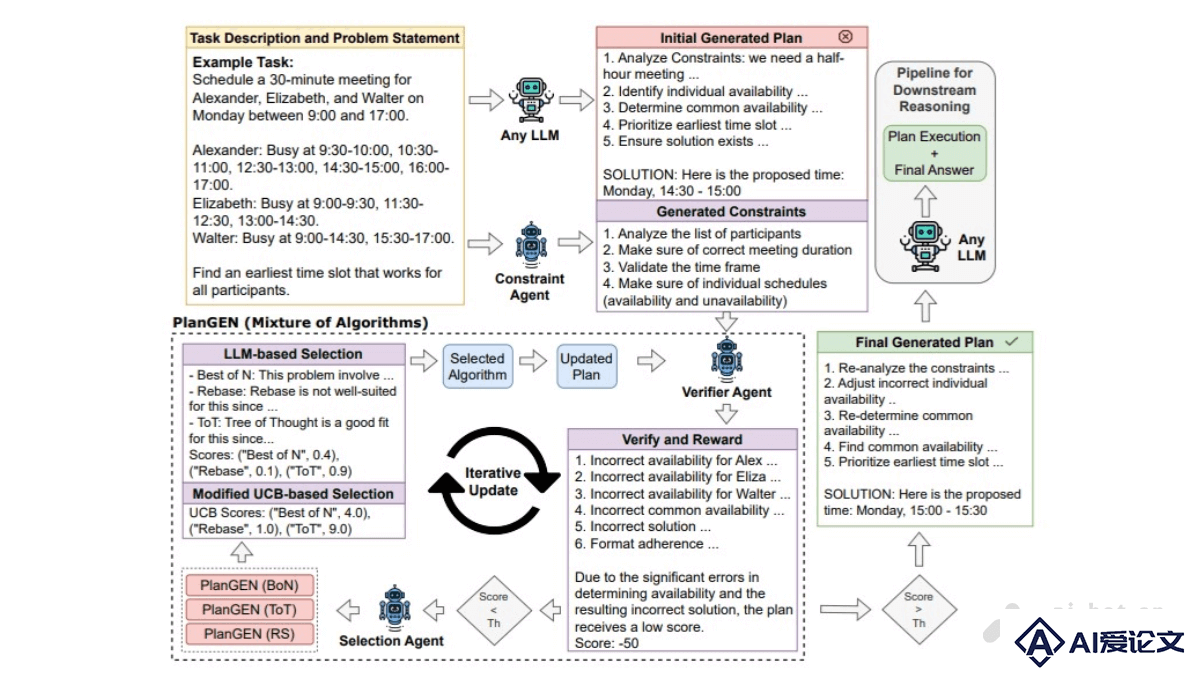
PlanGEN 是谷歌研究团队推出的多智能体框架,通过多智能体协作、约束引导和算法自适应选择,解决复杂问题的规划和推理。包含三个关键组件:约束智能体、验证智能体和选择智能体。智能体协同工作,形成一个强大的问题解决系统。
AI教程资讯
2023-04-14

MV-MATH 是中科院自动化所提出的新基准数据集,评估多模态大语言模型(MLLMs)在多视觉场景中的数学推理能力。数据集包含2009个高质量的数学问题,每个问题都结合了多个图像和文本,形成了图文交错的多视觉场景。
AI教程资讯
2023-04-14

MHA2MLA是复旦大学、华东师范大学、上海AI Lab等机构联合推出的数据高效的微调方法,基于引入DeepSeek的多头潜在注意力机制(MLA),优化任何基于Transformer的LLM的推理效率,降低推理成本。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














