Vision Parse是什么
Vision Parse是开源的PDF文档转换工具,基于视觉语言模型(Vision LLMs)将PDF文件转换成Markdown格式。Vision Parse能智能识别和提取PDF中的文本和表格,且保持原有的格式和结构。Vision Parse支持多种视觉语言模型,如OpenAI、LLama、Gemini等,来提高解析的准确性和速度。用户通过Python环境安装并使用Vision Parse,实现文档的高效转换。

来源:爱论文 时间:2025-01-17 17:15:24
Vision Parse是开源的PDF文档转换工具,基于视觉语言模型(Vision LLMs)将PDF文件转换成Markdown格式。Vision Parse能智能识别和提取PDF中的文本和表格,且保持原有的格式和结构。Vision Parse支持多种视觉语言模型,如OpenAI、LLama、Gemini等,来提高解析的准确性和速度。用户通过Python环境安装并使用Vision Parse,实现文档的高效转换。
 相关资讯
更多+
相关资讯
更多+
Vision Parse是开源的PDF文档转换工具,基于视觉语言模型(Vision LLMs)将PDF文件转换成Markdown格式。Vision Parse能智能识别和提取PDF中的文本和表格,且保持原有的格式和结构。Vision Parse支持多种视觉语言模型,如OpenAI、LLama、Gemini等,来提高解析的准确性和速度。
AI教程资讯
 2023-04-14
2023-04-14

The Language of Motion是斯坦福大学李飞飞团队推出的多模态语言模型,能整合人类动作中的言语和非言语语言。模型能处理文本、语音和动作数据,生成对应的目标模态,对于创建自然交流的虚拟角色至关重要。
AI教程资讯
2023-04-14
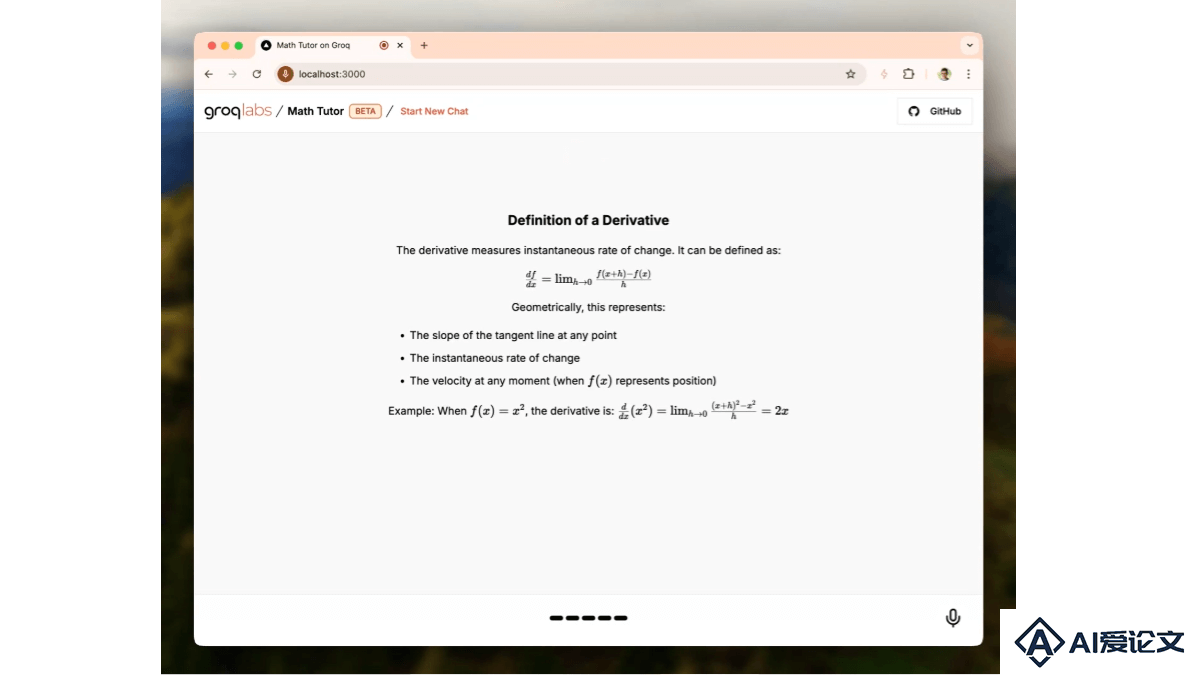
Mathtutor on Groq 是基于 Groq 架构的AI数学辅导工具,基于语音识别功能,支持用户用语音形式提出数学问题。工具内置强大的数学引擎,能实时计算并用 LaTeX 格式渲染出详细的解题过程和答案,极大地提升学习效率和交互性。
AI教程资讯
2023-04-14

VE-Bench 是北京大学的研究团队 MMCAL 最近发布首个专门针对视频编辑质量评估的指标。VE-Bench 的设计目标是与人类感知能力高度一致,更准确地评估视频编辑效果。VE-Bench QA 在评估编辑视频时,不仅考虑了传统视频质量评估方法强调的审美、失真等视觉质量指标,还专注于文本与视频的对齐以及源视频与编辑后视频之间的相关性建模。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












