MiniMax-01是什么
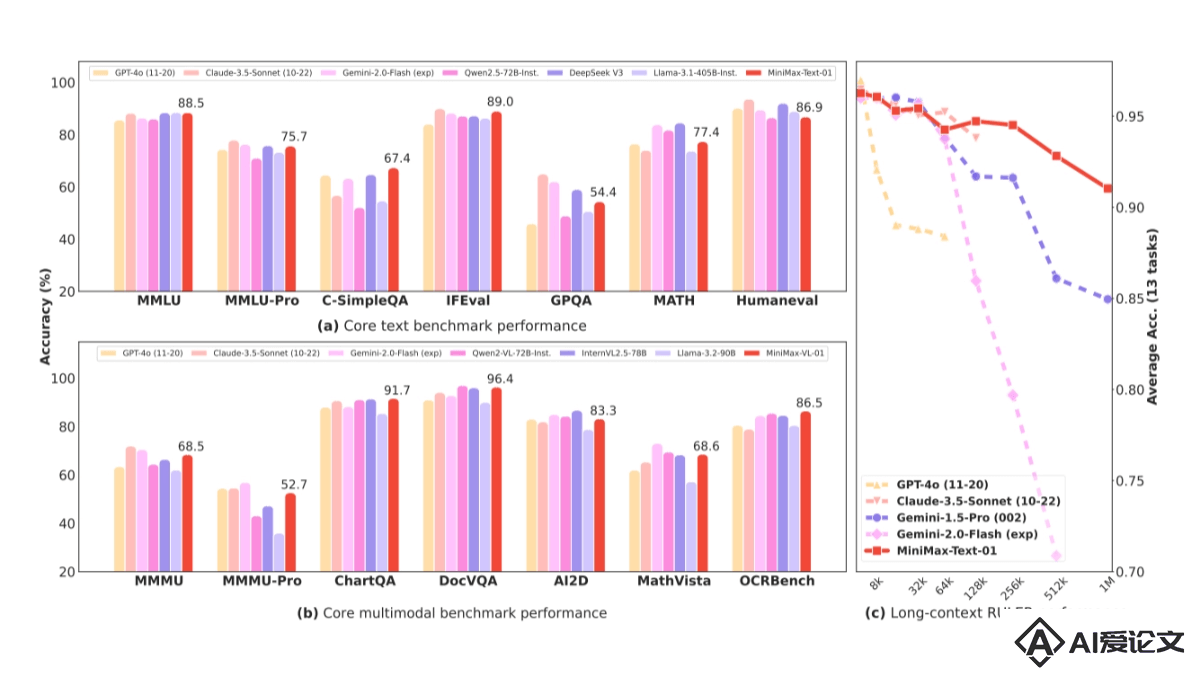
MiniMax-01是MiniMax推出的全新系列模型,包含基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。MiniMax-01首次大规模实现线性注意力机制,打破传统Transformer架构限制,参数量达4560亿,单次激活459亿,性能比肩海外顶尖模型,能高效处理全球最长400万token上下文。MiniMax-01系列模型以极致性价比提供API服务,标准定价低,且在长文任务、多模态理解等多方面表现优异。
来源:爱论文 时间:2025-03-29 14:15:03
MiniMax-01是MiniMax推出的全新系列模型,包含基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。MiniMax-01首次大规模实现线性注意力机制,打破传统Transformer架构限制,参数量达4560亿,单次激活459亿,性能比肩海外顶尖模型,能高效处理全球最长400万token上下文。MiniMax-01系列模型以极致性价比提供API服务,标准定价低,且在长文任务、多模态理解等多方面表现优异。
 相关资讯
更多+
相关资讯
更多+
MiniMax-01是MiniMax推出的全新系列模型,包含基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。MiniMax-01首次大规模实现线性注意力机制,打破传统Transformer架构限制,参数量达4560亿,单次激活459亿,性能比肩海外顶尖模型,能高效处理全球最长400万token上下文。
AI教程资讯
 2023-04-14
2023-04-14
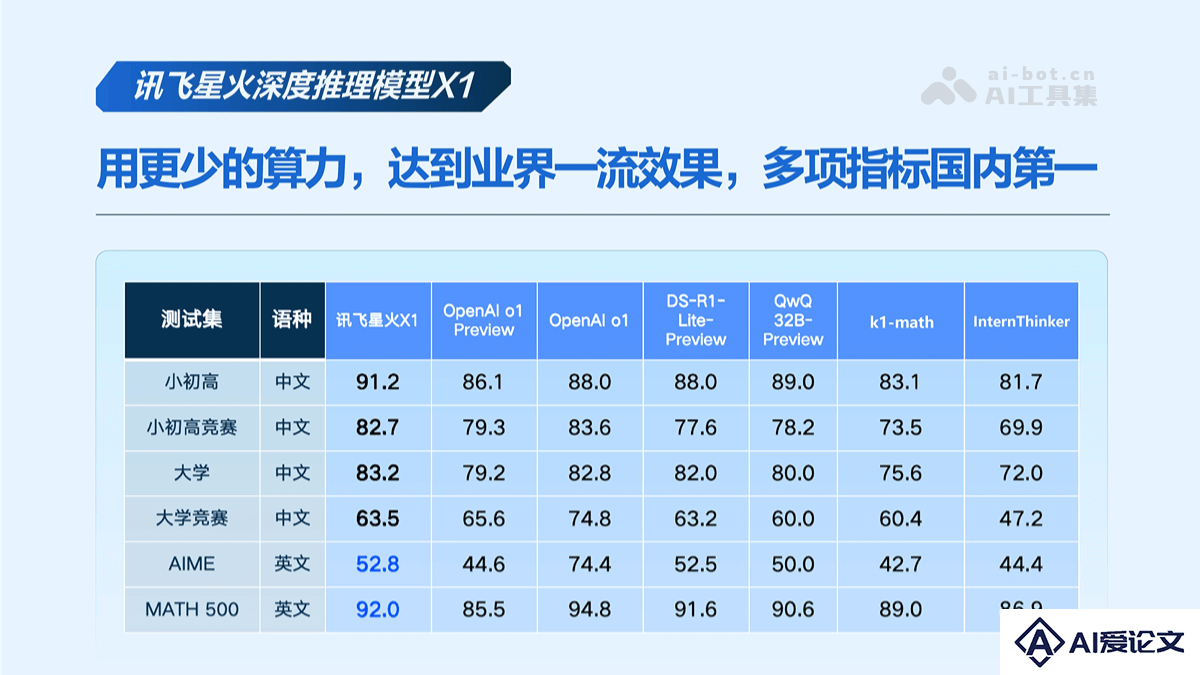
讯飞星火 X1 是科大讯飞于2025年1月15日发布的国内首个基于全国产算力平台训练的具备深度思考和推理能力的大模型。在解题过程中更接近人类的“慢思考”方式,仅用更少的算力就实现了业界一流的效果,多项指标国内第一。
AI教程资讯
2023-04-14

星火语音同传大模型是科大讯飞于2025年1月15日发布的国内首个具备端到端语音同传能力的大模型。模型在内容完整度、信息准确度以及语言质量上均处于行业领先水平,超过谷歌Gemini 2 0和OpenAI GPT-4o,最快实现5秒以内的同传时延,达到人类专家译员的水平。
AI教程资讯
2023-04-14

Titans是谷歌推出的新型神经网络架构,能突破Transformer在处理长序列数据时的记忆瓶颈。Titans引入神经长期记忆模块,模拟人脑记忆机制,特别强化对意外事件的记忆能力。Titans架构包含三种变体:MAC(记忆作为上下文)、MAG(记忆作为门)和MAL(记忆作为层),分别用不同的方式整合记忆模块。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














