Zerox是什么
Zerox是开源的本地化高精度OCR工具,基于GPT-4o-mini模型,无需提前训练实现零样本识别。Zerox支持PDF、DOCX、图片等多种格式文件,擅长处理扫描版文档及复杂布局文件,如含表格、图表等。Zerox工作流程是将文件转换为图像后进行OCR识别,最终输出Markdown格式文档,方便用户编辑和使用。Zerox提供API接口,便于开发者集成到应用中,实现自动化文档处理,广泛应用于企业文档管理、学术研究、法律金融以及教育等领域,极大提升文档信息提取的效率和准确性。
来源:爱论文 时间:2025-03-28 09:33:53
Zerox是开源的本地化高精度OCR工具,基于GPT-4o-mini模型,无需提前训练实现零样本识别。Zerox支持PDF、DOCX、图片等多种格式文件,擅长处理扫描版文档及复杂布局文件,如含表格、图表等。Zerox工作流程是将文件转换为图像后进行OCR识别,最终输出Markdown格式文档,方便用户编辑和使用。Zerox提供API接口,便于开发者集成到应用中,实现自动化文档处理,广泛应用于企业文档管理、学术研究、法律金融以及教育等领域,极大提升文档信息提取的效率和准确性。
 相关资讯
更多+
相关资讯
更多+
Zerox是开源的本地化高精度OCR工具,基于GPT-4o-mini模型,无需提前训练实现零样本识别。Zerox支持PDF、DOCX、图片等多种格式文件,擅长处理扫描版文档及复杂布局文件,如含表格、图表等。Zerox工作流程是将文件转换为图像后进行OCR识别,最终输出Markdown格式文档,方便用户编辑和使用。
AI教程资讯
 2023-04-14
2023-04-14

Video Alchemist是Snap公司等推出的新型视频生成模型,具备多主体、开放集合个性化能力,能根据文本提示和参考图像生成视频,无需在测试时进行优化。模型基于Diffusion Transformer模块,通过双重交叉注意力层将参考图像嵌入和主体级文本提示融入视频生成过程。
AI教程资讯
2023-04-14
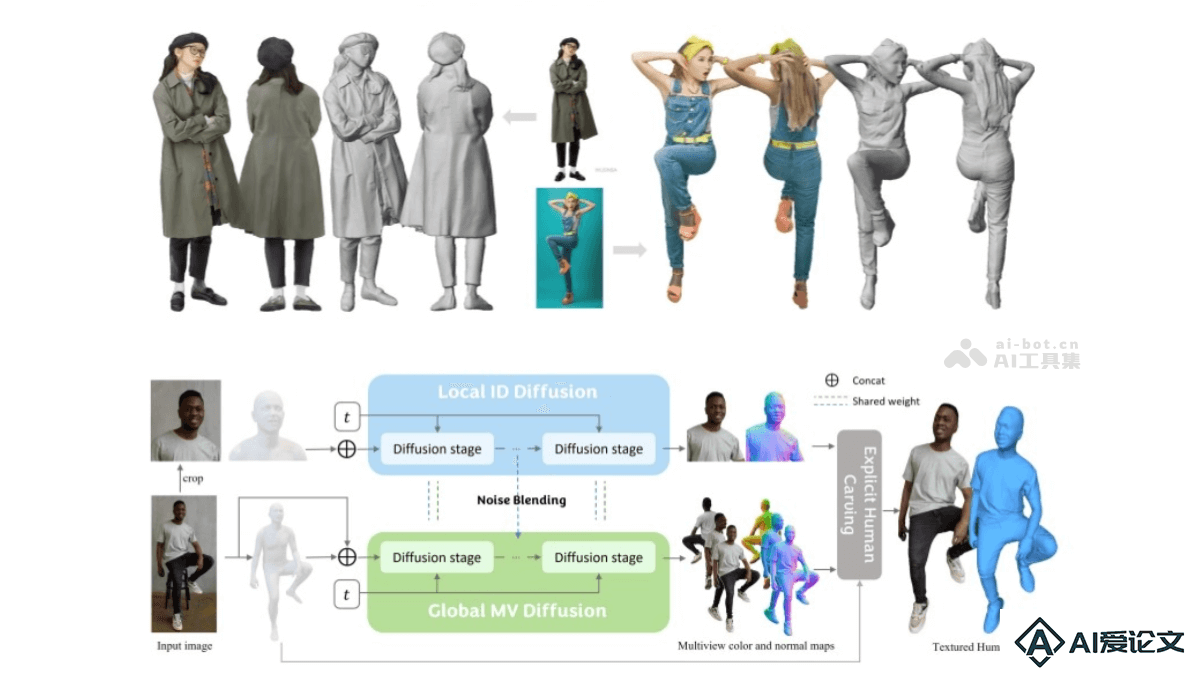
PSHuman是先进的单图像3D人像重建技术。基于跨尺度多视图扩散模型,仅需一张照片,能生成高度逼真的3D人像模型,包括精细的面部表情和全身姿态。核心优势在于能同时建模全局形状和局部细节的联合概率分布,避免几何失真,还能保持不同视图下身体形状的一致性。
AI教程资讯
2023-04-14
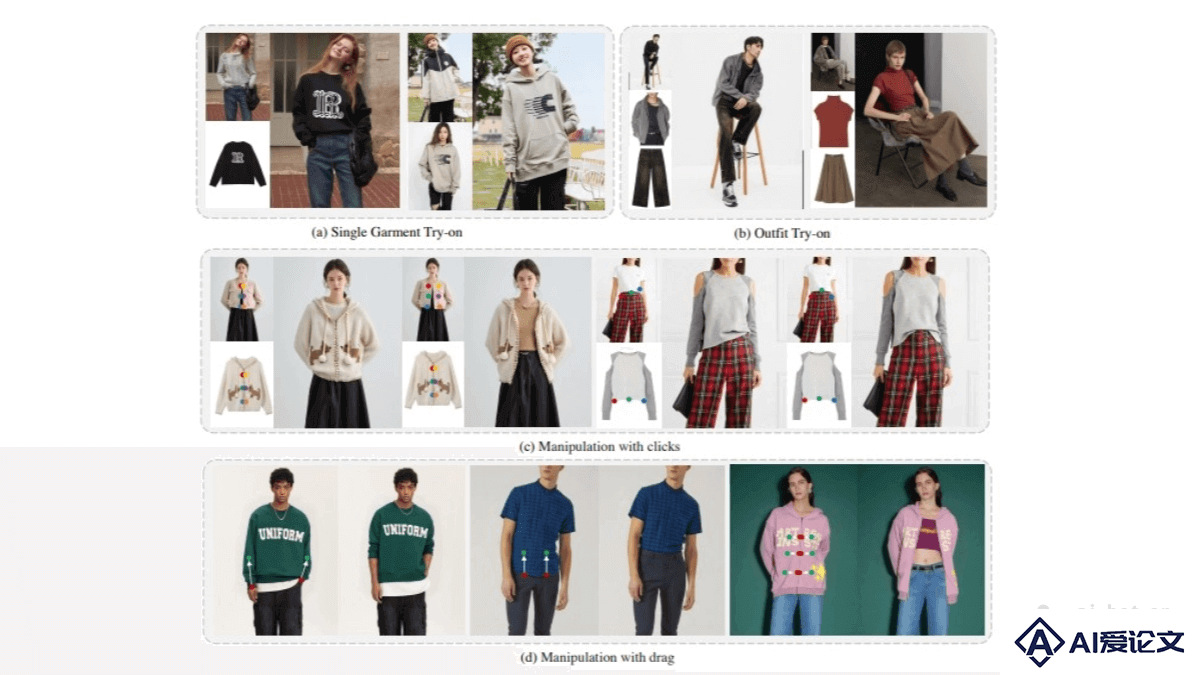
Wear-Any-Way是阿里巴巴拍立淘团队推出的创新的虚拟试穿框架。通过稀疏对应对齐机制,实现了高保真度且可定制的虚拟试穿效果。用户可以生成逼真的试穿图像,通过简单的点击和拖动操作,精准操控服装的穿着方式,如卷起袖子、调整大衣开合等,为虚拟试穿带来了全新的交互体验。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














