百聆是什么
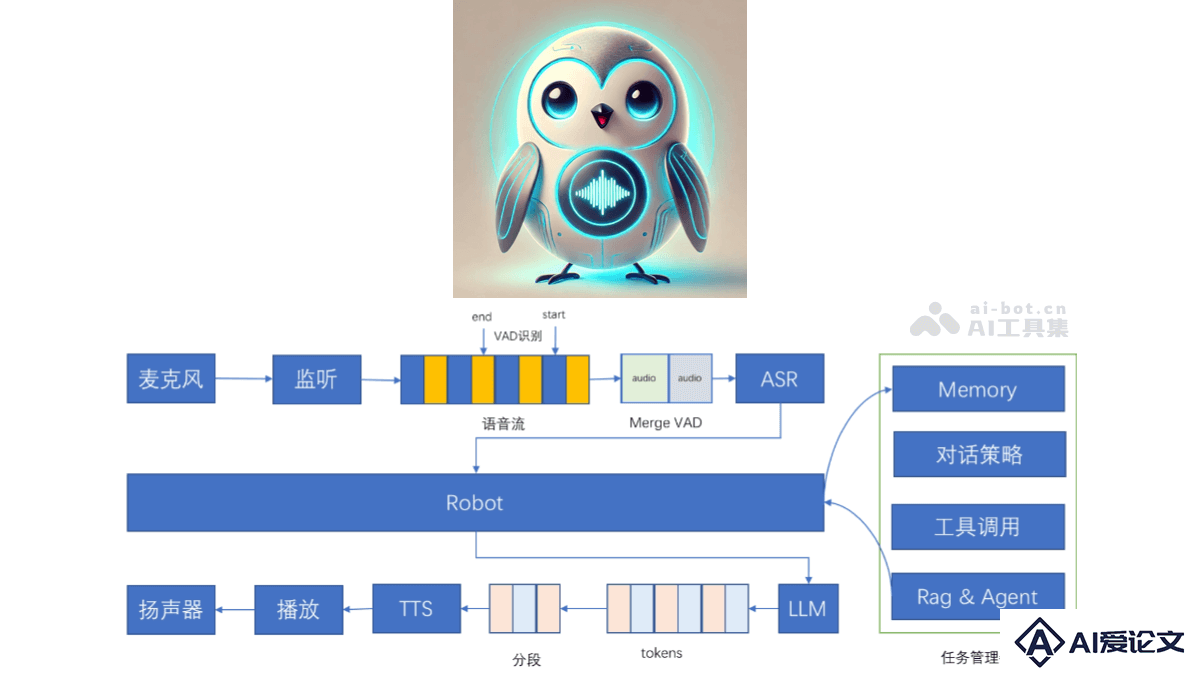
百聆(Bailing)是开源的语音对话助手,基于语音识别(ASR)、语音活动检测(VAD)、大语言模型(LLM)和语音合成(TTS)技术实现与用户的自然语音对话,实现类GPT-4o的对话效果。百聆无需GPU即可运行,端到端时延低至800ms,适用于各种边缘设备和低资源环境。百聆具备高效开源模型、无需GPU、模块化设计、支持记忆功能、支持工具调用、支持任务管理等项目特点,提供高质量的语音对话体验。
来源:爱论文 时间:2025-03-27 15:31:40
百聆(Bailing)是开源的语音对话助手,基于语音识别(ASR)、语音活动检测(VAD)、大语言模型(LLM)和语音合成(TTS)技术实现与用户的自然语音对话,实现类GPT-4o的对话效果。百聆无需GPU即可运行,端到端时延低至800ms,适用于各种边缘设备和低资源环境。百聆具备高效开源模型、无需GPU、模块化设计、支持记忆功能、支持工具调用、支持任务管理等项目特点,提供高质量的语音对话体验。
 相关资讯
更多+
相关资讯
更多+
百聆(Bailing)是开源的语音对话助手,基于语音识别(ASR)、语音活动检测(VAD)、大语言模型(LLM)和语音合成(TTS)技术实现与用户的自然语音对话,实现类GPT-4o的对话效果。百聆无需GPU即可运行,端到端时延低至800ms,适用于各种边缘设备和低资源环境。
AI教程资讯
 2023-04-14
2023-04-14

LineArt是吉林大学、瑞典皇家理工学院、东京工业大学等机构推出的,无需训练的高质量设计绘图外观迁移框架,能将复杂外观特征转移到详细的设计图纸上,辅助设计和艺术创作。LineArt基于模拟人类层次化的视觉认知过程,整合艺术经验指导扩散模型,生成高保真度的图像,同时精准保留设计图纸的结构细节。
AI教程资讯
2023-04-14

SynthLight 是耶鲁大学和 Adobe Research 联合推出的基于扩散模型的人像重照明技术,通过模拟不同光照条件下的合成数据进行训练,能将人像照片重新渲染为具有全新光照效果的图像,比如添加高光、阴影或调整整体光照氛围。
AI教程资讯
2023-04-14
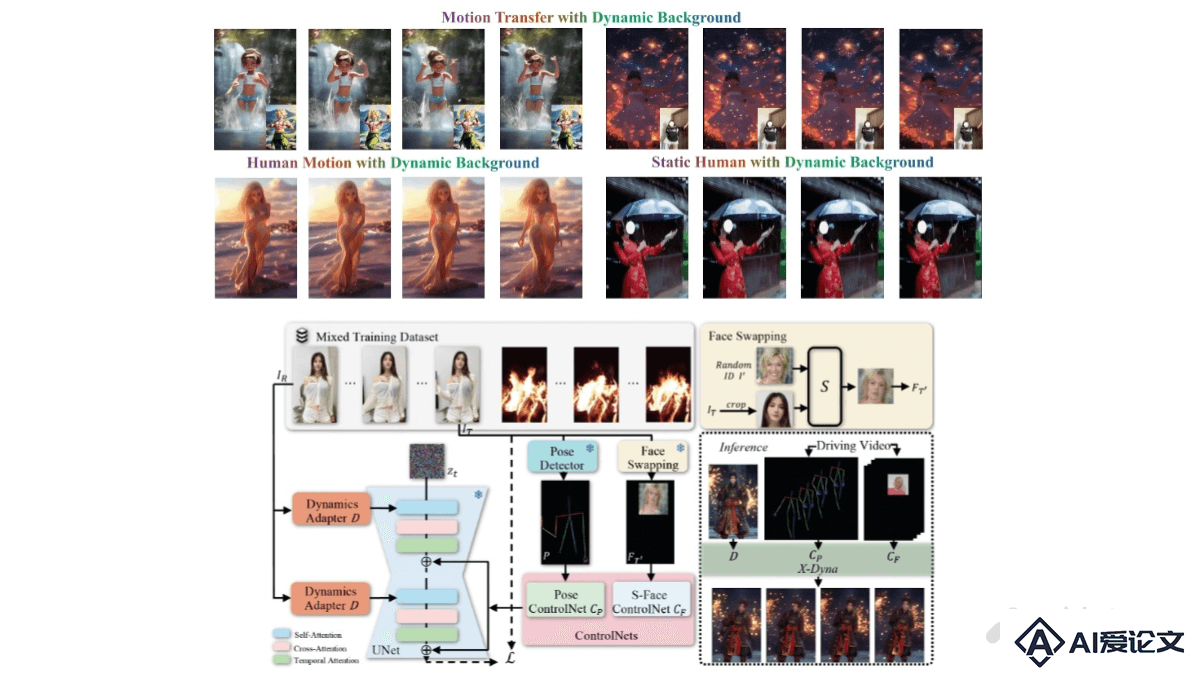
X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到扩散模型的空间注意力中,同时保留运动模块生成流畅和复杂动态细节的能力。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














