Step-1o Vision是什么
Step-1o Vision 是阶跃星辰最新研发的原生端到端多模态生成与理解一体化模型中的视觉版本。专注于视觉任务,具备强大的图像识别、感知、推理和指令跟随能力,能处理复杂的视觉输入并生成准确的文本描述或进行逻辑推理。在多个权威榜单中表现优异,适用于多种视觉任务,能为用户提供高效、智能的视觉理解解决方案。

来源:爱论文 时间:2025-03-27 10:25:50
Step-1o Vision 是阶跃星辰最新研发的原生端到端多模态生成与理解一体化模型中的视觉版本。专注于视觉任务,具备强大的图像识别、感知、推理和指令跟随能力,能处理复杂的视觉输入并生成准确的文本描述或进行逻辑推理。在多个权威榜单中表现优异,适用于多种视觉任务,能为用户提供高效、智能的视觉理解解决方案。
 相关资讯
更多+
相关资讯
更多+
Step-1o Vision 是阶跃星辰最新研发的原生端到端多模态生成与理解一体化模型中的视觉版本。专注于视觉任务,具备强大的图像识别、感知、推理和指令跟随能力,能处理复杂的视觉输入并生成准确的文本描述或进行逻辑推理。
AI教程资讯
 2023-04-14
2023-04-14
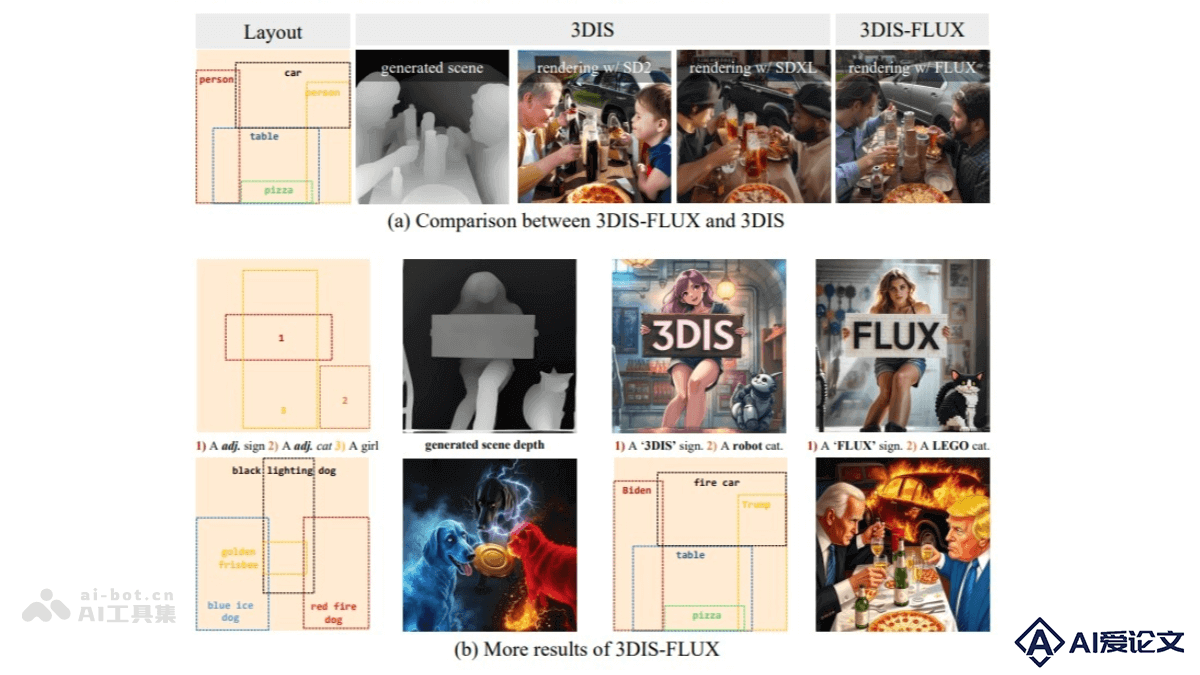
3DIS-FLUX是基于深度学习的多实例生成框架,通过解耦实例合成实现高质量的图像生成。结合3DIS框架的深度驱动场景构建和FLUX模型的扩散变换器架构,分为两阶段:首先生成场景深度图,然后基于FLUX模型进行细节渲染。
AI教程资讯
2023-04-14

DITTO-2 是 Adobe 和加州大学研究人员联合推出的新型音乐生成模型,通过优化扩散模型的推理时间,实现快速且可控的音乐生成。模型基于扩散模型的推理时间优化(Inference-Time Optimization, ITO),通过模型蒸馏技术(如一致性模型 Consistency Model, CM 和一致性轨迹模型 Consistency Trajectory Model, CTM),将生成速度提升至比实时更快。
AI教程资讯
2023-04-14

DiffEditor是北京大学深圳研究生院与腾讯PCG的研究团队提出的基于扩散模型(Diffusion Model)的图像编辑工具,通过引入图像提示(image prompts)和文本提示,结合区域随机微分方程(Regional SDE)和时间旅行策略,显著提升了图像编辑的准确性和灵活性。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














