VideoChat-Flash是什么
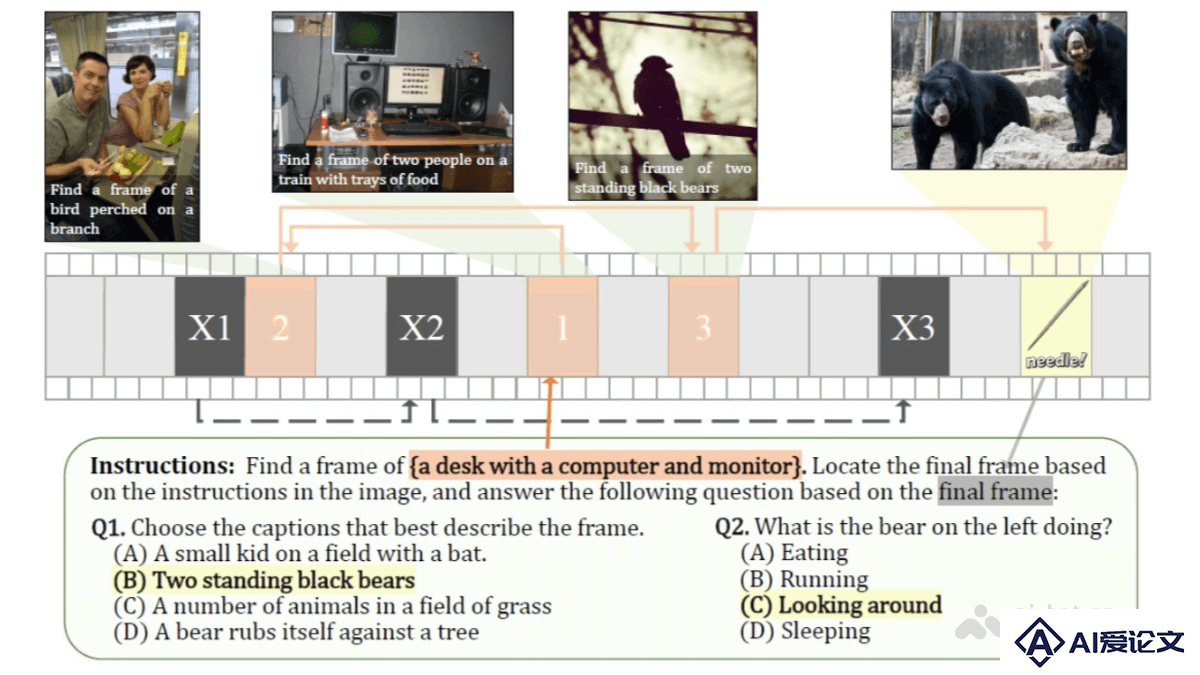
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。采用多阶段从短到长的学习方案,结合真实世界长视频数据集 LongVid,进一步提升对长视频的理解能力。
来源:爱论文 时间:2025-03-26 15:32:42
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。采用多阶段从短到长的学习方案,结合真实世界长视频数据集 LongVid,进一步提升对长视频的理解能力。
 相关资讯
更多+
相关资讯
更多+
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。
AI教程资讯
 2023-04-14
2023-04-14
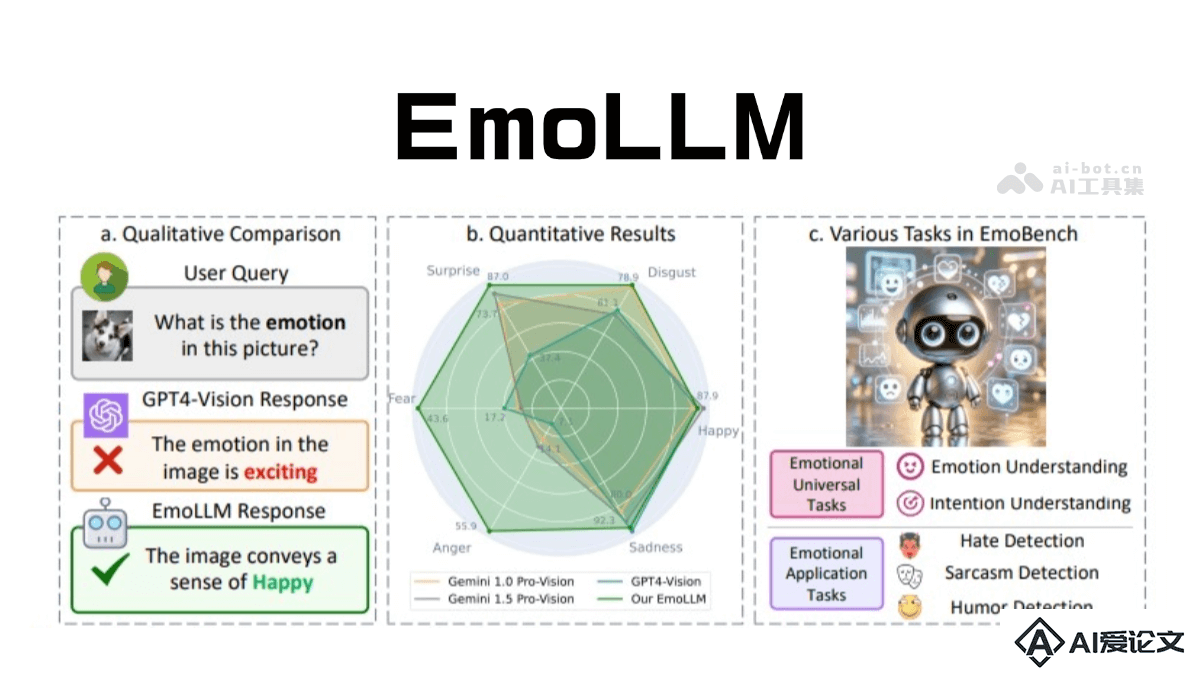
EmoLLM 是专注于心理健康支持的大型语言模型,通过多模态情感理解为用户提供情绪辅导和心理支持。结合了文本、图像、视频等多种数据形式,基于先进的多视角视觉投影技术,从不同角度捕捉情感线索,更全面地理解用户的情绪状态。
AI教程资讯
2023-04-14
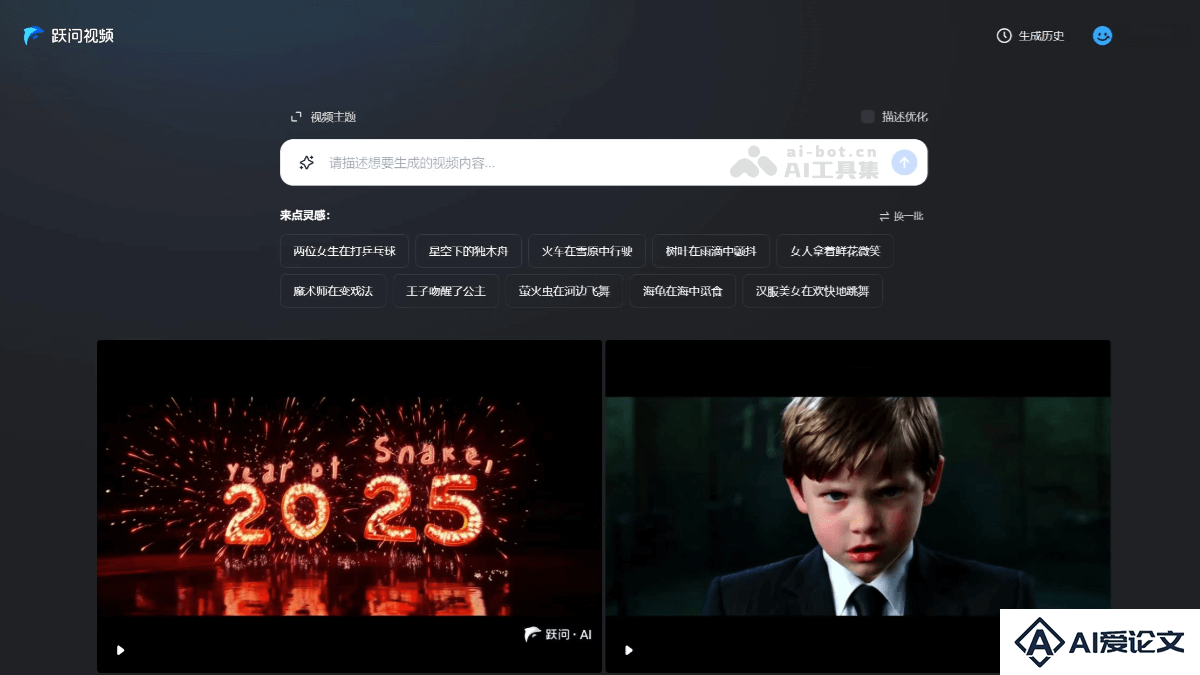
Step-Video V2 是上海阶跃星辰智能科技发布的升级版视频生成模型。该版本在多个核心技术领域进行了优化和创新,采用了更高压缩比的VAE模型以及深度优化的DiT架构,引入强化学习算法。能生成复杂的动态场景,如芭蕾舞、空手道等,同时支持丰富的镜头语言和基础文字生成。
AI教程资讯
2023-04-14
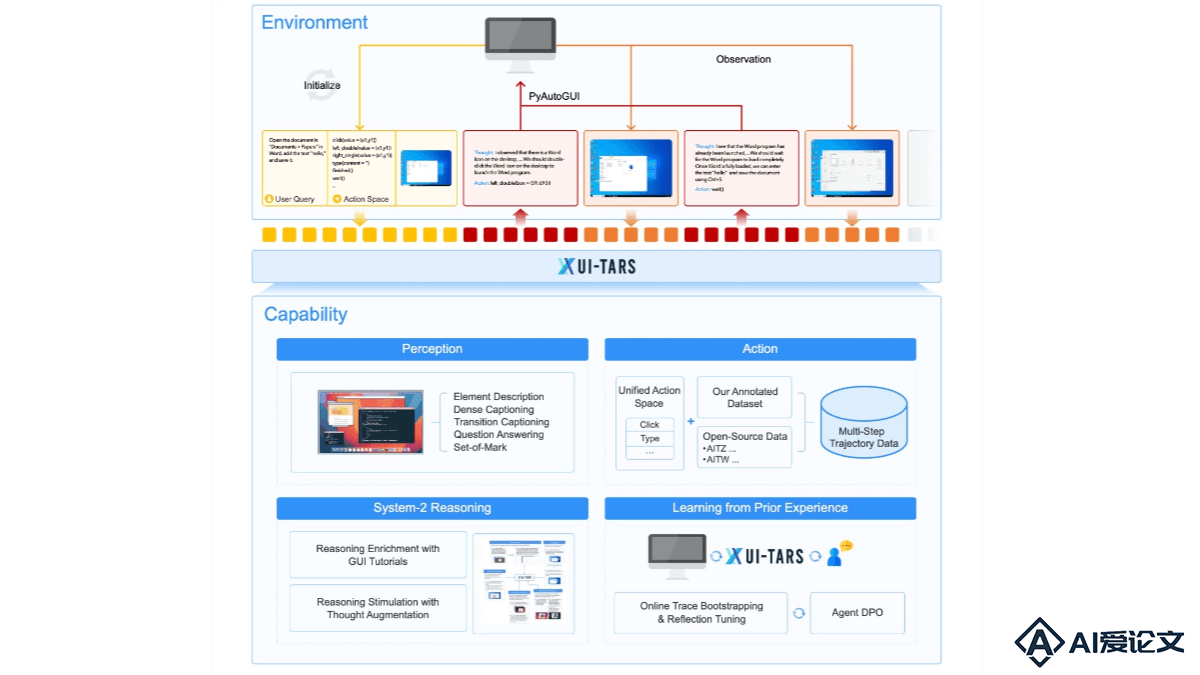
UI-TARS 是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














