UI-TARS是什么
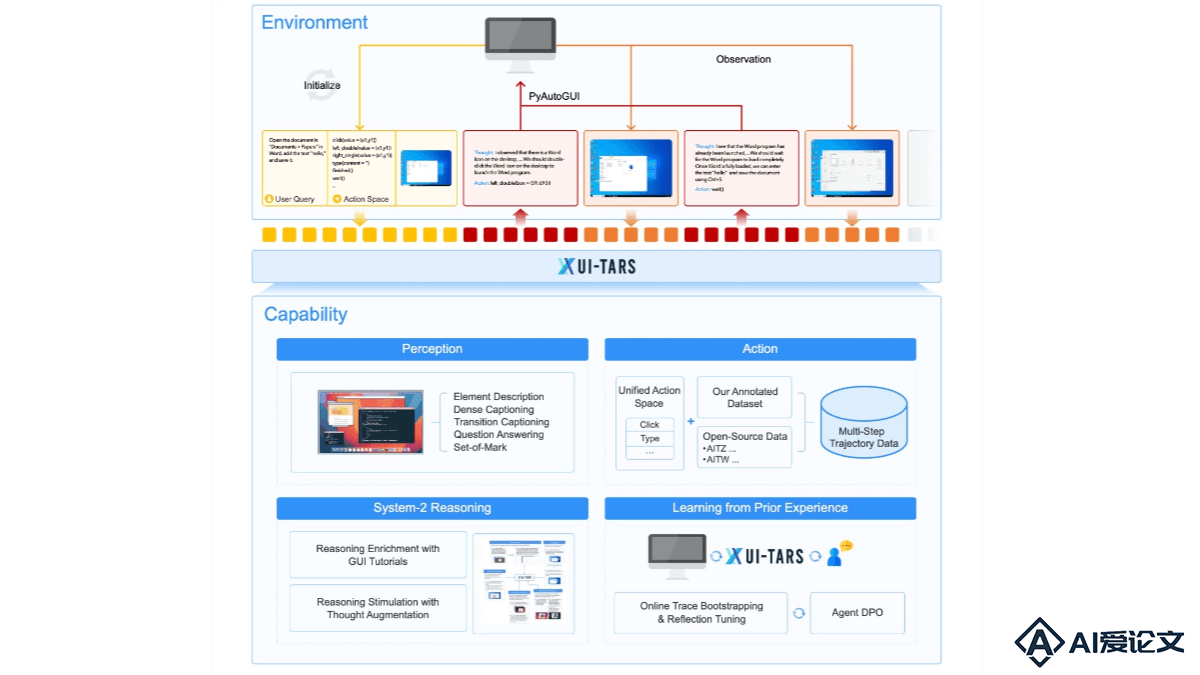
UI-TARS是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。 UI-TARS 的核心优势在于跨平台的标准化行动定义,支持桌面、移动和网页等多种环境。结合了快速直观反应和复杂任务规划的能力,支持多步推理、反思和错误纠正。还具备短期和长期记忆功能,能更好地适应动态任务需求。
来源:爱论文 时间:2025-03-26 14:10:57
UI-TARS是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。 UI-TARS 的核心优势在于跨平台的标准化行动定义,支持桌面、移动和网页等多种环境。结合了快速直观反应和复杂任务规划的能力,支持多步推理、反思和错误纠正。还具备短期和长期记忆功能,能更好地适应动态任务需求。
 相关资讯
更多+
相关资讯
更多+
UI-TARS 是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。
AI教程资讯
 2023-04-14
2023-04-14

EMO2 (End-Effector Guided Audio-Driven Avatar Video Generation)是阿里巴巴智能计算研究院开发的音频驱动头像视频生成技术,全称为“末端效应器引导的音频驱动头像视频生成”。通过音频输入和一张静态人像照片,生成富有表现力的动态视频。
AI教程资讯
2023-04-14

PaSa是字节跳动研究团队(ByteDance Research)推出的基于强化学习的学术论文检索智能体。能模仿人类研究者的行为,自动调用搜索引擎、浏览相关论文并追踪引文网络,为用户提供精准、全面的学术论文检索结果。
AI教程资讯
2023-04-14
Baichuan-M1-preview 是百川智能推出的国内首个全场景深度思考模型。模型具备语言、视觉和搜索三大领域的推理能力,在数学、代码等多个权威评测中表现优异,超越了o1-preview等模型。核心亮点是解锁了“医疗循证模式”,通过自建的亿级条目循证医学知识库,能快速、精准地回答医疗临床和科研问题。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














