TokenVerse是什么
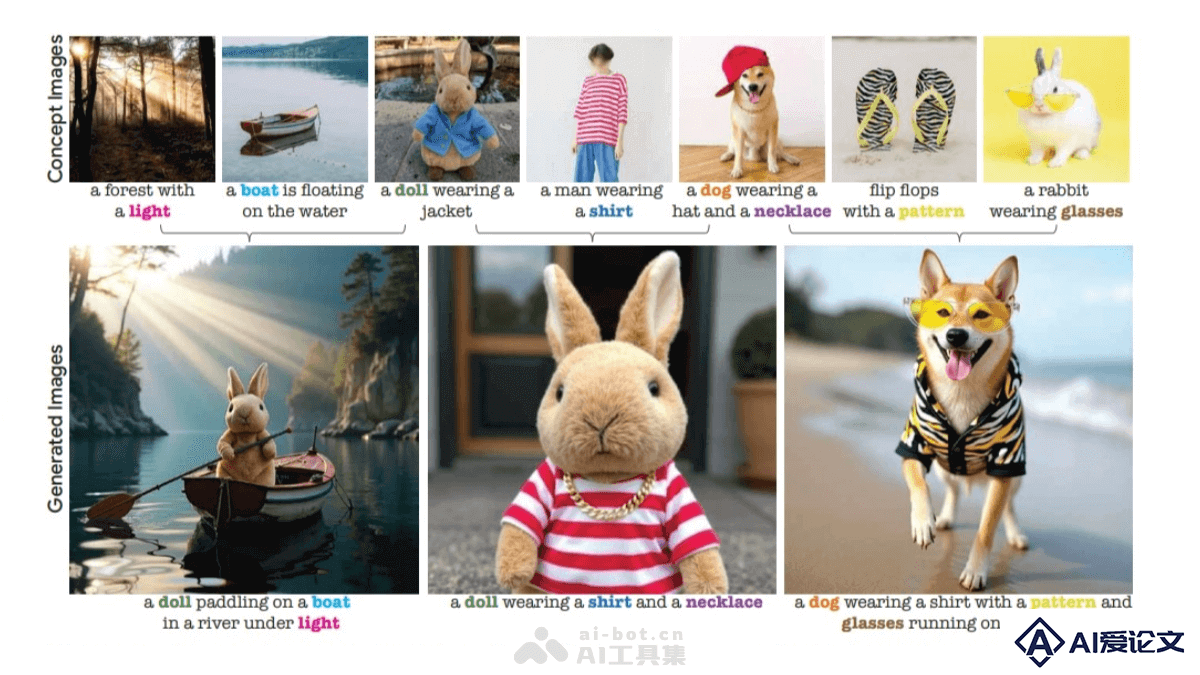
TokenVerse 是基于预训练文本到图像扩散模型的多概念个性化图像生成方法。能从单张图像中解耦复杂的视觉元素和属性,从多张图像中提取概念进行无缝组合生成。支持多种概念,包括物体、配饰、材质、姿势和光照等,突破了现有技术在概念类型或广度上的限制。 TokenVerse 基于 DiT 模型的调制空间,通过优化框架为每个词汇找到独特的调制空间方向,实现对复杂概念的局部控制。在个性化图像生成领域具有显著优势,能满足设计师、艺术家和内容创作者在不同场景下的多样化需求。
来源:爱论文 时间:2025-03-26 12:31:40
TokenVerse 是基于预训练文本到图像扩散模型的多概念个性化图像生成方法。能从单张图像中解耦复杂的视觉元素和属性,从多张图像中提取概念进行无缝组合生成。支持多种概念,包括物体、配饰、材质、姿势和光照等,突破了现有技术在概念类型或广度上的限制。 TokenVerse 基于 DiT 模型的调制空间,通过优化框架为每个词汇找到独特的调制空间方向,实现对复杂概念的局部控制。在个性化图像生成领域具有显著优势,能满足设计师、艺术家和内容创作者在不同场景下的多样化需求。
 相关资讯
更多+
相关资讯
更多+
TokenVerse 是基于预训练文本到图像扩散模型的多概念个性化图像生成方法。能从单张图像中解耦复杂的视觉元素和属性,从多张图像中提取概念进行无缝组合生成。支持多种概念,包括物体、配饰、材质、姿势和光照等,突破了现有技术在概念类型或广度上的限制。
AI教程资讯
 2023-04-14
2023-04-14

Baichuan-M1-14B是百川智能推出的行业首个开源医疗增强大模型,医疗能力超越了更大参数量的Qwen2 5-72B,与o1-mini相差无几。专为医疗场景优化,同时具备强大的通用能力。模型基于 20 万亿 token 的高质量医疗与通用数据训练,涵盖 20 多个医疗科室的细粒度专业知识。
AI教程资讯
2023-04-14

CogVideoX-2 是智谱 AI开源的文本到视频生成模型,基于先进的 3D 变分自编码器(VAE),将视频数据压缩到原本的 2%,减少资源使用,同时确保视频帧之间的连贯流畅。 通过独特的 3D 旋转位置编码技术,视频在时间轴上能够自然流动,赋予画面生命力。
AI教程资讯
2023-04-14

llmware是为企业级应用设计的统一框架,适用于构建基于小型、专门化模型的RAG(Retrieval-Augmented Generation)流程。llmware支持私有部署,能安全集成企业知识源,针对业务流程进行成本效益的调整和优化。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














